Pushing HPC Beyond Traditional Boundary
Rikky Purbojati, Research Computing, NUS IT
First of all, I would like to say hello to everybody in the NUS’ research computing community. It is a great privilege to join one of the most prominent universities and HPC shops in Singapore, and I am looking forward to interacting and communicating with all of you. At the same time, I would also like to give Mr Tan Chee Chiang, my predecessor and former head of the research computing group in NUS IT, a heartfelt appreciation of what he has built with the team. I wish him good times and good health in his well-deserved retirement. And for the both of us: Onto a new adventure!
AI/ML Adoption in HPC: A Conundrum
I want to continue where Chee Chiang left off and share the work that the research computing group is currently working on. In support of the AI/ML adoption into HPC folds, there needs to be a strategy with agility in mind when deciding any future scientific computing development.
AI adoption in our digital economy has been increasing rapidly over the past few years. Starting from the re-emergence of Deep Learning application in the ImageNet challenge, the resulting key technologies and techniques have been embedded in and influenced many aspects of research. Over the years, the massive popularity of AI/ML has driven the development of GPU technology to a point where other non-AI/ML side of research could also enjoy the benefit of having faster computing options for their research. In addition, from the non-hardware side, there are many ever-evolving AI/ML services offered by commercial providers in the form of API, libraries, code-augmentation, etc. These cutting-edge technologies are primed to be leveraged to accelerate research and produce valuable innovation.
However, circling back to being agile, a typical traditional HPC system is notoriously a monolith. It is an expensive custom-made computing system hosted in a server room and usually has an expected lifespan of 5-10 years. It is a challenge to adopt a rapidly changing technology into a system that is often rigid. For example, a new technology that requires the latest version of firmware or libraries cannot be immediately considered since uplifting the HPC libraries wholesale meant complex change requests and, in the end, can break existing software and disrupt operation. AI/ML technology is just one example; there are many potential issues with upcoming technology, such as Quantum computing, that we have not even begin to imagine.
Putting “Agile” in Our Infrastructure
Our current development work focuses on emphasizing agility in our HPC infrastructure. We have identified that extending our infrastructure to commercial cloud service providers (CSP) is our best bet in achieving some level of agility. By having the broadest availability and quick time-to-market, CSPs have always been at the forefront of adopting consumer-ready computing services in their cloud offerings. They have the financial muscle, international infrastructure, and leading experts to avail these cutting-edge technologies to the customers immediately. For example, the latest NVIDIA A100 AWS instances were made available within days after the general availability announcement was made, compared to retail, where there was a purchasing waitlist. But even after all that, the retail version still needs to be delivered and implemented.
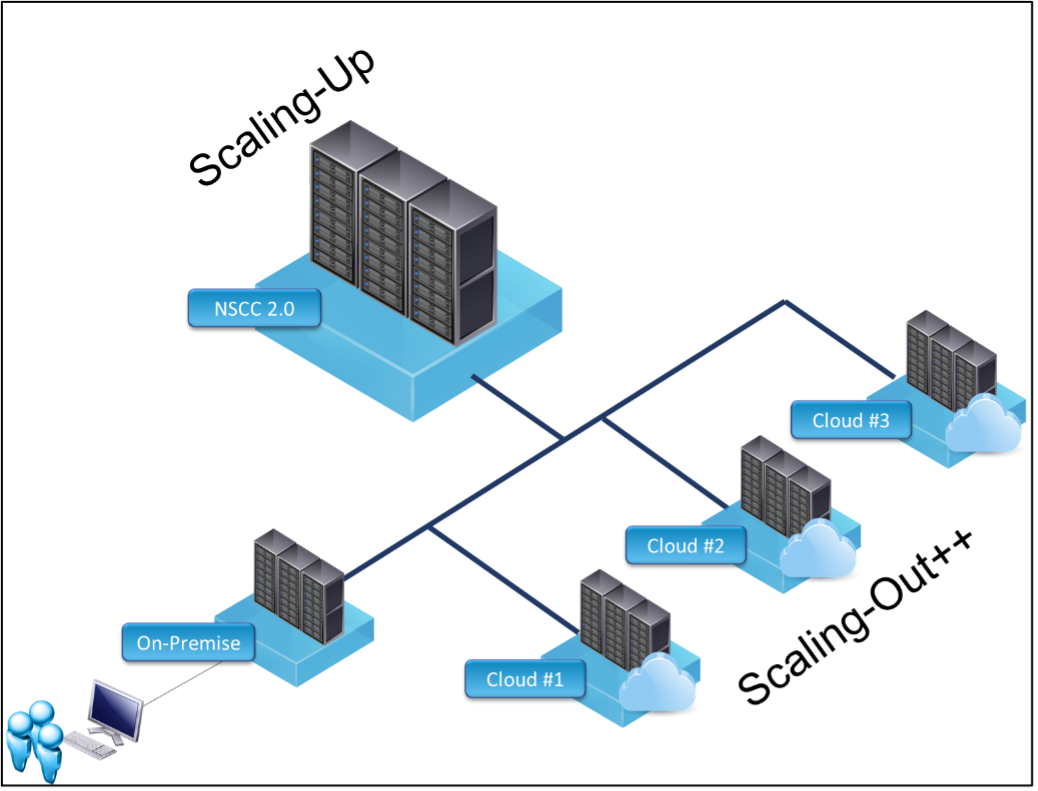 The current direction to extend to the clouds can be considered as a scaling-out++ strategy. Scaling-out in the sense that we can instantaneously (or as fast as our procurement can handle it) adds more computing resources to researchers without waiting for shipment and construction. The plus-plus (++) part refers to the unique offerings that the CSPs can provide. Many CSPs have custom AI/ML services, for instance, IBM Watson, AWS SageMaker, etc. These are all value-added services that can be leveraged to accelerate and elevate our research works.
The current direction to extend to the clouds can be considered as a scaling-out++ strategy. Scaling-out in the sense that we can instantaneously (or as fast as our procurement can handle it) adds more computing resources to researchers without waiting for shipment and construction. The plus-plus (++) part refers to the unique offerings that the CSPs can provide. Many CSPs have custom AI/ML services, for instance, IBM Watson, AWS SageMaker, etc. These are all value-added services that can be leveraged to accelerate and elevate our research works.
Another parallel direction that we are pursuing is integrating NSCC 2.0 to our HPC infrastructure as the scale-up strategy. For some non-AI/ML applications that require petascale computational brawn and cannot effectively leverage the on-prem or cloud instances, NSCC 2.0 will be the best system to use. While we already have a working model using NSCC 1.0, we will leverage the fact that the NSCC 2.0a system will be hosted in NUS’s backyard to integrate with our HPC infrastructure seamlessly.
Submit Once, Run Anywhere
Admittedly, the scale-up and scale-out strategies are well-known in the HPC world. What we are developing is the secret sauce that holds everything together. We call it the “Submit once, Run anywhere“ design. The design calls for transparent workload processing, either in the on-prem, cloud, or NSCC, without users having to define it explicitly. For that to happen, we are leveraging multiple advanced technologies, such as containers, high-speed interconnect, peer-scheduling, orchestrators, etc.
Since this is still on-going, I will describe more on the details and initial result in the following newsletter.
Until then, if you are interested in our infrastructure and services, please visit our website (https://nusit.nus.edu.sg/hpc/), or if you are interested in collaborating with us in HPC or AI/ML projects, please contact our AI engineering team at DataEngineering@nus.edu.sg.
