Text Analytics Starting with NLTK
by Kuang Hao, Research Computing, NUS Information Technology
Introduction
NLP (Natural Language Processing) is not easy. When you are getting interested in it, immediately you realize that raw texts cannot be fed to our machine who only understands 0s and 1s. To make things harder, meaning of words can be ambiguous; sentences’ interpretation varies depending on the context; and there are hundreds of languages with different syntax & grammar rules. Fortunately, thanks to recent pioneers in NLP, there are standardized pipelines to follow and easy-to-use tools at hand.
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. NLTK is available for Windows, Mac OS X, and Linux. Best of all, NLTK is a free, open source, community-driven project. [1]
This article introduces the most popular tools in NLTK, how to set up and use them, as well as its availability on our HPC clusters.
Popular usage
First, we will need to use WordNet. WordNet is a lexical database for the English language, which was created by Princeton, and is part of the NLTK corpus. To download WordNet, simply run “nltk.download(‘wordnet’)” in our python script or notebook cell after importing NLTK. We only need to download it at the first time of use.
-
Tokenization
Tokenization is the first step in text analytics. The process of breaking down a text paragraph into smaller chunks such as words or sentences is called tokenization. A token is a single entity that is a building block for a sentence or paragraph. Sample tokenization steps using NLTK:
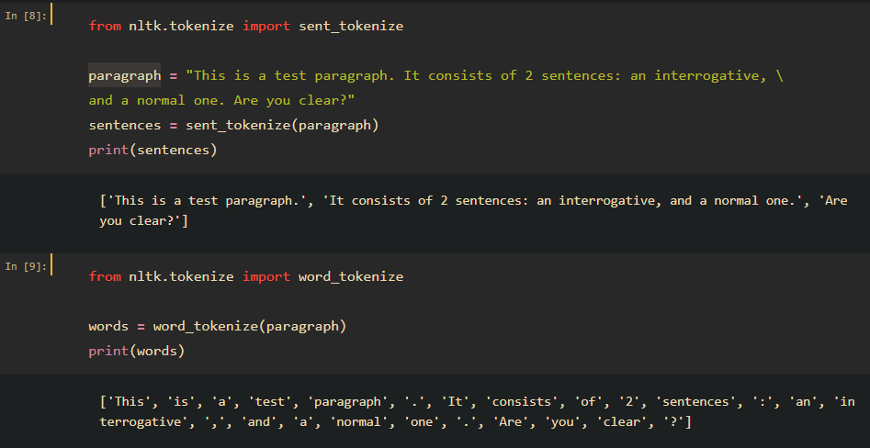
-
Stopwords
A stopword is a commonly used word (such as “the”, “a”, “in”, “very”) that is not valuable for text analytics. For tasks like text classification, where text is to be classified into different categories, stopwords should be removed from the given text so that more focus will be given to other meaningful tokens. To remove stopwords, we need to create a list of stopwords and filter out from our list of tokens. NLTK has a built-in stopwords list, remember to download at the first time using it:
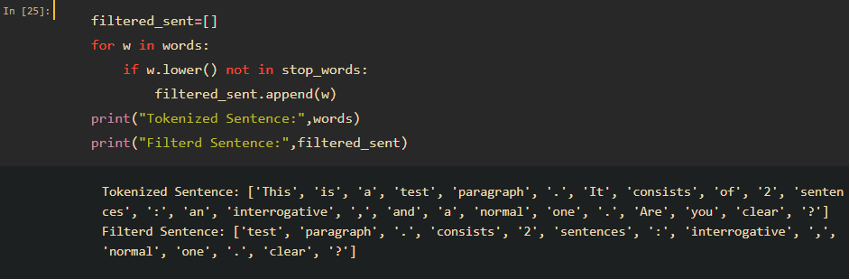
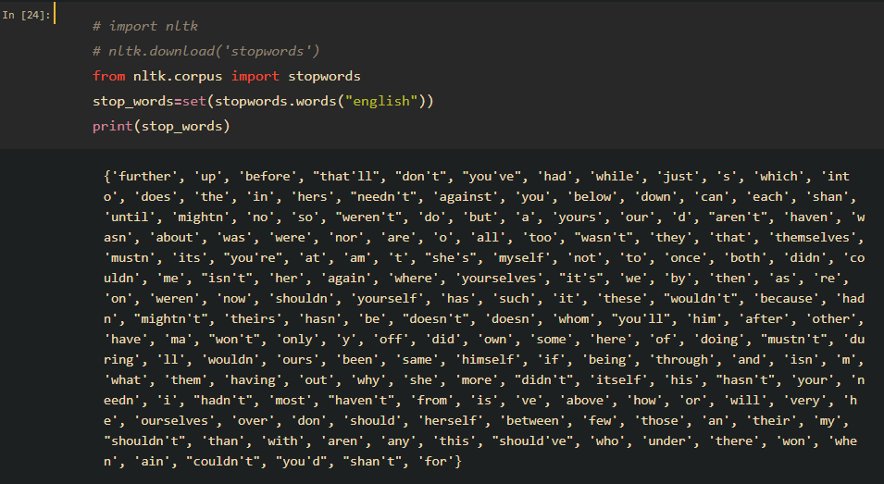 After downloading, we can filter out tokens against the list easily as shown below. Note that we can always add domain specific words to the list to cater for our use case, as this is just a general list of stopwords.
After downloading, we can filter out tokens against the list easily as shown below. Note that we can always add domain specific words to the list to cater for our use case, as this is just a general list of stopwords.
-
Lexicon Normalization
Lexicon normalization is another layer of cleaning/standardizing text data. It consists of stemming and lemmatization. Stemming reduces the number of words to their root word or chops off the derivational affixes. See an example below:
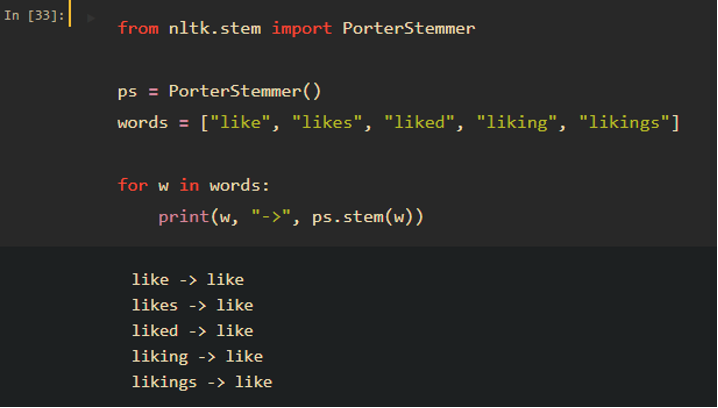 Lemmatization converts a word to its base form, in a more complicated way. For example, for “geese” as a noun, it will be converted to “goose”, and for “better” as a comparative adjective, it will be converted to “good”. See examples of lemmatization:
Lemmatization converts a word to its base form, in a more complicated way. For example, for “geese” as a noun, it will be converted to “goose”, and for “better” as a comparative adjective, it will be converted to “good”. See examples of lemmatization:
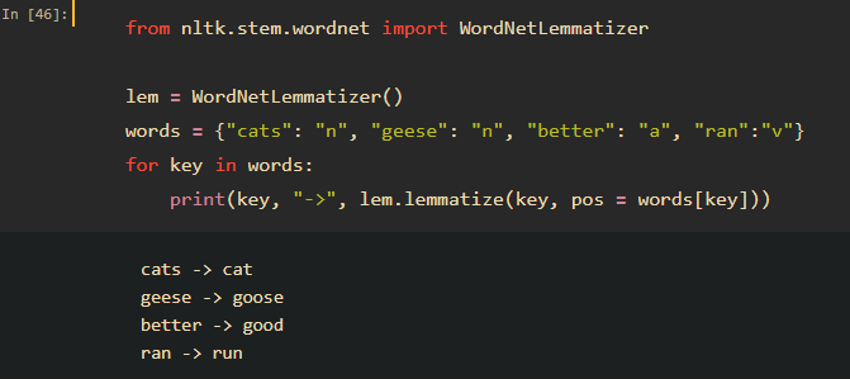 The goal for both stemming and lemmatization is to reduce inflectional forms. However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to converting words properly with the use of vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. [2] We should learn the difference and choose which one to use based on our actual needs.
The goal for both stemming and lemmatization is to reduce inflectional forms. However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to converting words properly with the use of vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. [2] We should learn the difference and choose which one to use based on our actual needs.
-
POS Tagging
POS (Part of Speech) tagging is the process of marking up a word in a corpus to a corresponding part of a speech tag, based on its context and definition. This task is not straightforward, as a particular word may have a different part of speech based on the context in which the word is used. [3] POS tagging can be important for syntactic and semantic analysis. With NLTK, it can be done easily as shown below. In many scenarios NLTK’s performance is good enough. For some tasks requiring higher accuracy, built-in functions generally don’t work well. Please consider training your own tagger for such use cases.
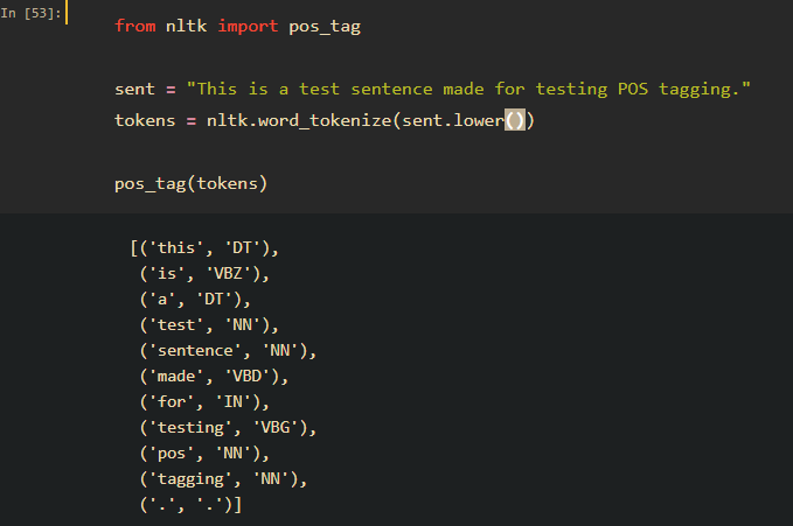 The full table of tags (Penn Treebank tagset) can be found here.
The full table of tags (Penn Treebank tagset) can be found here.
Availability on HPC
As a popular toolkit in NLP community, it’s well supported by PyPI and Anaconda, and straightforward for installation just like any normal Python package. Please refer to our deep learning manual for installation on HPC here.
Contact us if you have any issues using our HPC resources, via A.S.K.
Reference
[2] https://stackoverflow.com/questions/1787110/what-is-the-difference-between-lemmatization-vs-stemming
[3] https://medium.com/analytics-vidhya/pos-tagging-using-conditional-random-fields-92077e5eaa31
