Running Machine Learning pipelines using HUE
By Kumar Sambhav, HPC Specialist, NUS Information Technology
Research Computing at NUS IT provides a Hadoop based Data Repository and Analytics service. This system can be used to host your big data in the Data Repository and to analyse the data using Analytics Service. The Analytics Service part of DRAS provides services from real-time analytics to running machine learning using Spark.
Data Repository and Analytics Service (DRAS) system is a combination of data storage and the applications that can work on the data. There are a variety of machine learning libraries provided by the DRAS system. The Spark-MLlib is one such library which enables users to run applications in parallelised form. MLlib fits into Spark‘s APIs and interoperates with NumPy in Python.
Running MLlib scripts on DRAS is quite straight-forward as well. Users can upload their data and machine learning scripts to their any directory under their Hadoop home directory using HUE:
- Uploading data and files:
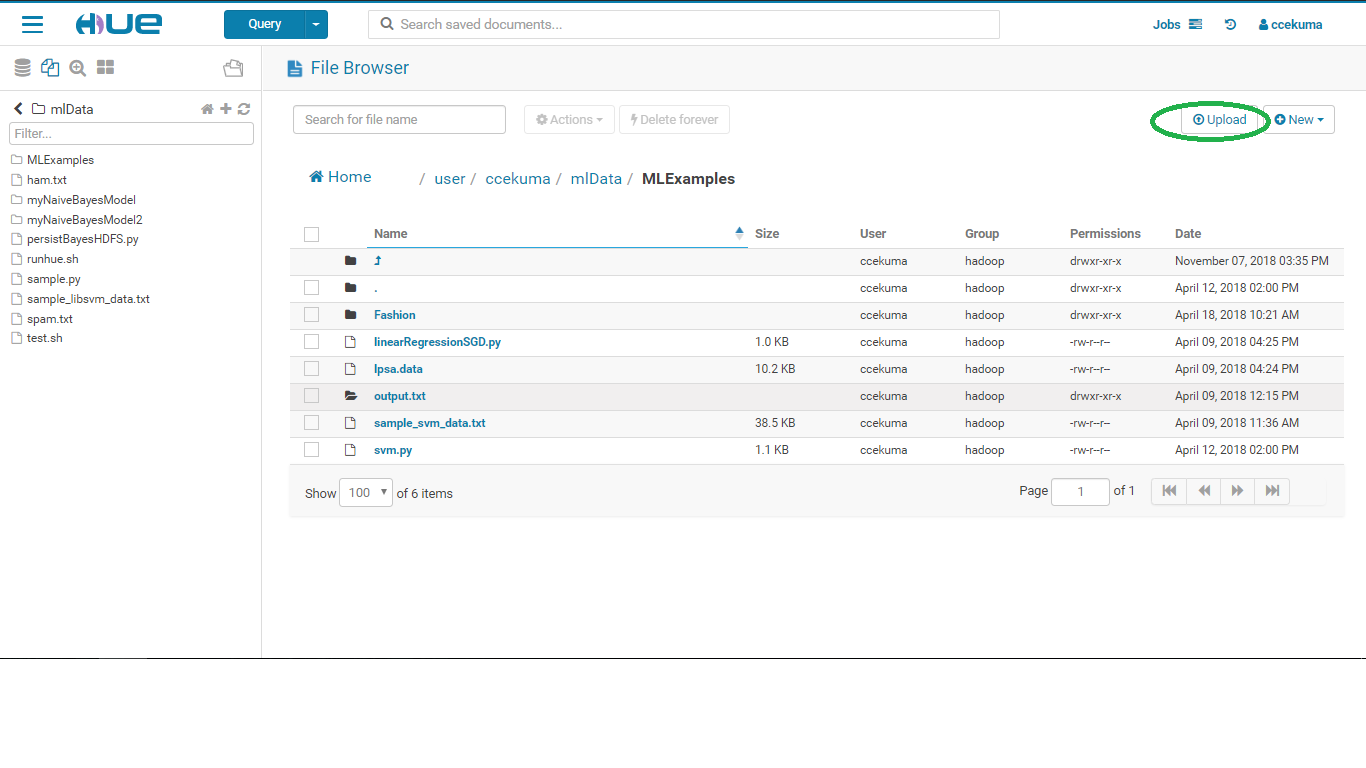
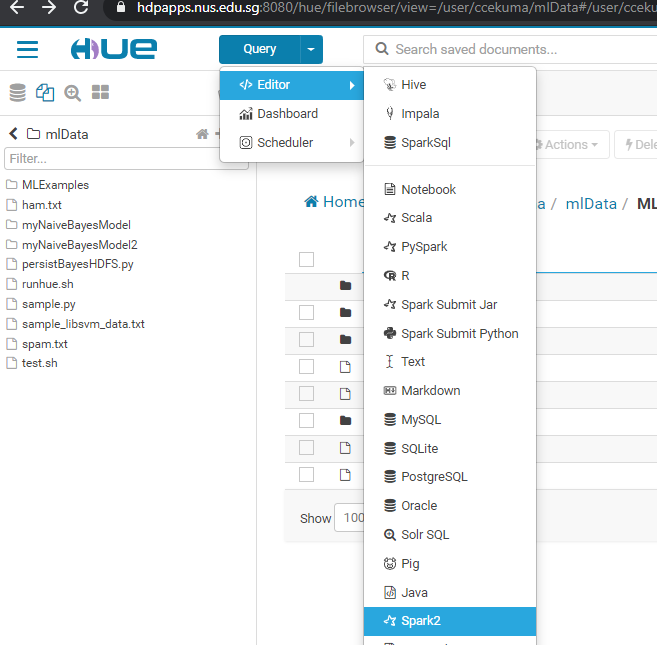
- Once the file is uploaded the machine learning scripts can be run by going to Query->Editors->Spark2.
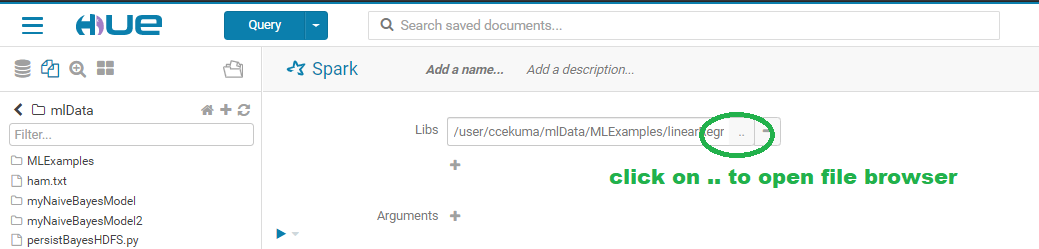
- Users can then look for the machine learning script by opening the file browser:
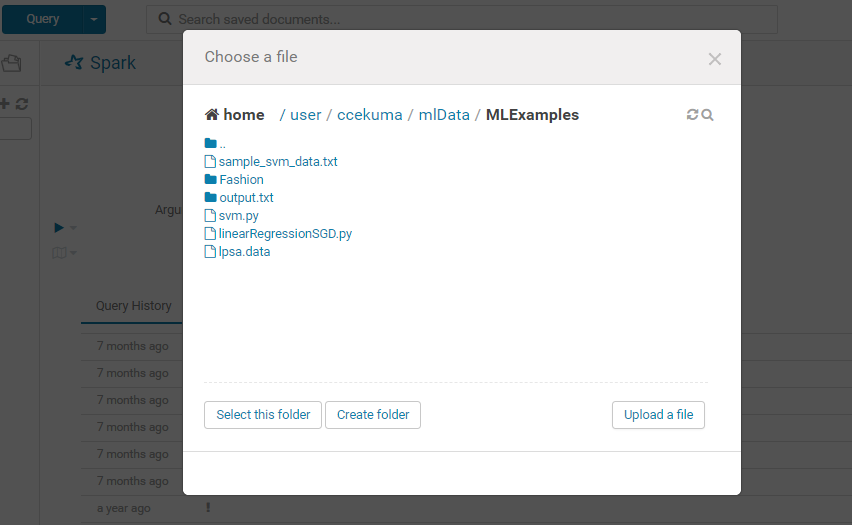
- Using the file browser the user can select the script:
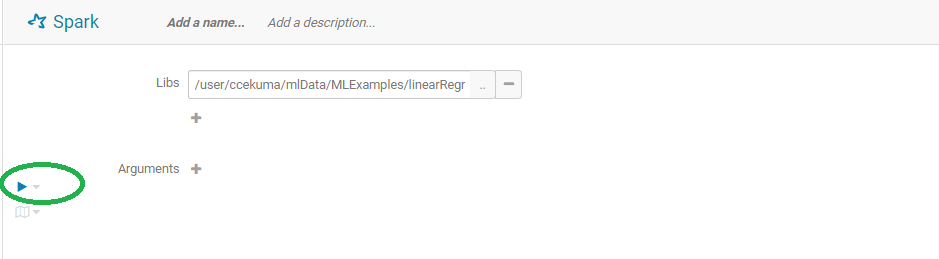
- User can then execute the script by clicking on the play button:
Machine Learning Pipelines:
A Pipeline is a specified sequence of stages, where each stage is either a Transformer or an Estimator. These stages are run in sequence and the input DataFrame is transformed according to the specifications as it passes through each stage. In the Transformer stages, the transform() method is called on the DataFrame. The Transformer encapsulates all the actions which are used to transform data to be fed to the Estimator. For Estimator stages, the fit() method is called to produce a Transformer (which becomes part of the PipelineModel, or fitted Pipeline), and that Transformer’s transform() method is called on the DataFrame.
The figure below shows a sample pipeline flow:
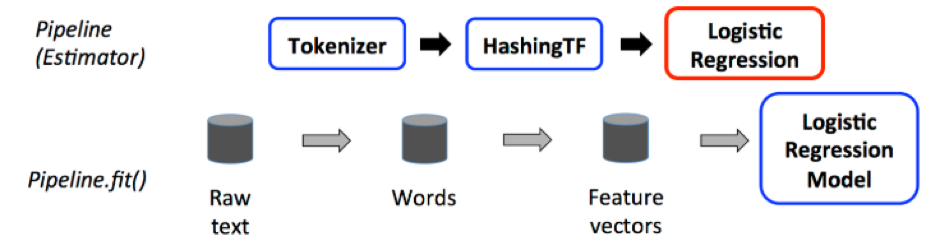
A pipeline thus can be used to create systems in which data processing and model training is done together. Pipelines help users to improve the integrity of Machine Learning projects by keeping the processing uniform and close to the model training logic.
Should you wish to know more about HUE, DRAS or how to run machine learning pipelines or programs, drop us an email at dataengineering@nus.edu.sg .
