Artificial Intelligence (AI) adoption and Machine Learning (ML) have become hot topics and trends in many domains. In NUS, many researchers and students are carrying out AI training for various research projects. In this article, three interesting AI training projects carried out in the central AI/GPU platform will be shared by the statistics nature of the performance of the AI training and the researchers’ valuable feedback. The three researchers are selected from the list of top AI/GPU users in Q1 of 2022.
AI Project from Researcher A
Keywords: Vision-Language Pre-training, PyTorch, GPU bound performance
AI Project Name: Vision-Language Pre-training
Objective: To develop a general visual language pre-training model, so that it can better serve a wider range of downstream tasks.
AI/ML Platform: PyTorch
Benefits of Using AI/GPU Cluster: It is easy to use with large available GPU memory, and meets most of the AI experimental requirements
Dataset Size: small dataset contains about 28K images, and the big dataset contains about 1.37 million image-caption pairs.
Computing Bottleneck: GPU bound.
Computing Performance Outcome: It covers the basic need.
Suggestion for Improvement: It would be nice if the maximum duration limit of the program execution can be extended, or the number of GPUs per job can be increased.
The statistics nature of the performance of Researcher A’s AI training jobs performed in Q1 2022 is plotted below. The key observations from the plots are:
Most of the training jobs use all CPU cores allocated extensively, which indicates that the training performance is CPU bound as well.
The training jobs can perform well on 2 GPUs, as both GPUs are fully loaded when in use.
The GPU memory usage plot shows that the training jobs almost use the 32GB available GPU memory per card.
The average GPU load is in the range of 40% to 70%; the average power usage is in the range of 100W to 200W per GPU card.


AI Project from Researcher B
Keywords: Multi-object tracking, PyTorch, GPU bound performance
AI Project Name: Multi-object tracking for any interesting objects
Objective: to achieve competitive speed and accuracy for multi-class multi-object tracking.
AI/ML Platform: PyTorch
Benefits of Using AI/GPU Cluster: It is useful for running learning jobs with a large memory of V100 GPUs.
Dataset Size: about 150GB.
Computing Bottleneck: GPU bound.
Computing Performance Outcome: Yes, it meets the need.
Suggestion for Improvement: Using the HPC was a great help throughout my project.
The statistics nature of the performance of Researcher B’s AI training jobs performed in Q1 2022 is plotted below. The key observations from the plots are:
Most of the training jobs use one CPU core or slightly more, which indicates that the training performance is not depending on CPU resources.
Most of the training jobs are performed well on one GPU, with a few being carried on two GPUs. The GPU is running most of the time during the execution of the jobs
The GPU memory usage plot shows that the training jobs almost use the 32GB available GPU memory per card.
The average GPU load is in the range of 30% to 80%; the average power usage is in the range of 100W to 200W per GPU card.


AI Project from Researcher C
Keywords: Recurrent Neural Networks Training, TensorFlow, CPU/GPU bound performance
AI Project Name: Emergence of Ring Attractor Properties In Recurrent Neural Networks Trained On A Spatial Working Memory Task
Objective: to investigate how the brain keeps multiple pieces of information in working memory, by training recurrent neural networks to remember multiple spatial locations.
AI/ML Platform: TensorFlow
Benefits of Using AI/GPU Cluster: a) Able to queue and run multiple job scripts simultaneously; b) Able to schedule multiple job scripts in advance; c) Fast computation; d) Able to debug script interactively volta_login node.
Dataset Size: Data is contemporaneously generated with a python generator as the model is being trained. Hence it is not required for the dataset to be stored.
Computing Bottleneck: Both CPU-bound and GPU-bound.
Computing Performance Outcome: Yes, it meets the expectation.
Suggestion for Improvement: a) more jobs can be executed simultaneously; b) more resources for interactive test/debug sessions with shorter waiting time; c) sometimes with empty stdout file causing difficulty in tracking the problem; d) impossible to recover data deleted by accident.
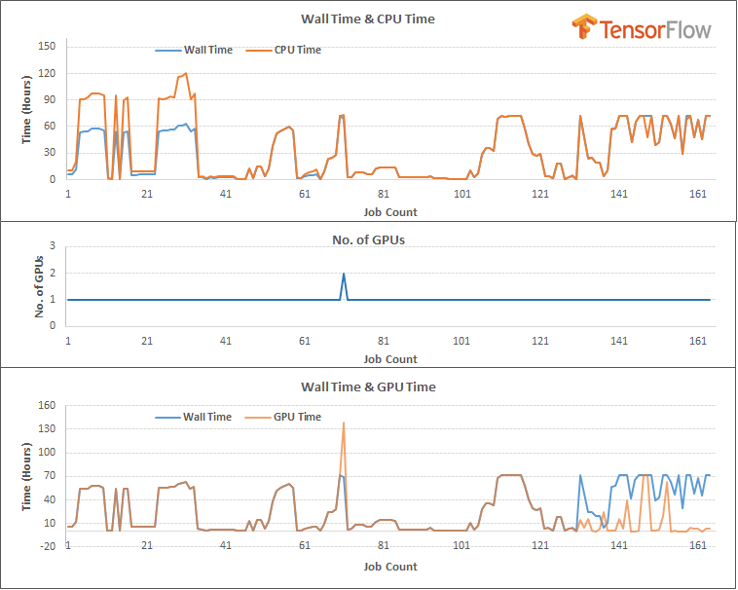

The statistics nature of the performance of Researcher C’s AI training jobs performed in Q1 2022 is plotted below. The key observations from the plots are:
Most of the training jobs use one CPU core or slightly more and several training jobs use about 2 CPU cores, which indicates that the training performance can be either CPU bound or not CPU bound considering different training settings.
Majority of the training jobs are performed on one GPU, with the GPU running most of the time during the execution of the jobs.
The GPU memory usage plot shows that the training jobs almost use the 32GB available GPU memory per card.
The average GPU load is rather low at about 20% to 40% for 1/3 of training jobs performed and dropped to about 10% for the rest; the average power usage is in the range of 50W to 80W per GPU card, which is quite low.
Service Improvement Plan
User feedback and suggestion are invaluable for us to improve the service. The following plans and actions are being executed upon the feedback received.
There is a plan to add more GPU resources in 2022 by introducing the latest GPU cards and technologies. This will allow users to run the training jobs faster and use more GPU cards for big training jobs but also enable users to run more training jobs simultaneously.
The team is working on a feasibility study to add more GPU resources to support the interactive test/debug sessions and hence shorten the waiting time.
AI/ML users can sign up for an account with the NSCC system (https://user.nscc.sg/saml/) and run their large AI training jobs using multiple GPUs in the NSCC AI system.
More seminars and workshops will be conducted to assist users running their AI/ML training jobs more effectively in the system.
Summary
The central AI/GPU system meets the researchers’ basic needs for their projects on the AI/ML training.
The training running with both PyTorch and TensorFlow platforms use GPU cards throughout the execution of the jobs. The statistics demonstrate that PyTorch can use processors on GPU cards more intensively and effectively.
High GPU memory usage indicates that large GPU memory could play a very important role in the computing performance for the AI training jobs.