Minimising Processing Time when Training Deep Reinforcement Learning Models
By M Ganeshkumar
Year 2 PhD Student
Thesis: Neural basis of Schemas for few-shot learning
NUS Graduate School of Science and Engineering (NGS)
Department of Electrical & Computer Engineering (ECE)
Abstract
GPUs/TPUs are used to increase the processing speed when training deep learning models due to its parallel processing capability. Reinforcement learning on the other hand is predominantly CPU intensive due to the sequential interaction between the agent and environment. With the recent popularity of deep reinforcement learning (deep RL) algorithms, understanding how to shorten processing speed based on the available resources becomes imperative. The purpose of this report is to highlight some considerations to optimise the computational resources available for deep RL, specifically the size of network used.
Introduction
Reinforcement learning (RL) algorithms such as Q-learning, SARSA and Actor Critic sequentially learn a value table that describes how good an action will be given a state. The value table is the policy which the agent uses to navigate through the environment to maximise its reward. Each step in the training paradigm involves an agent to explore the environment by first taking actions and subsequently, updating the value table with the reward obtained for that specific state and action. This is a cyclical process whereby the policy is evaluated in the environment followed by an update of the policy based on the reward. The main drawback of these algorithms was the inability to learn complex environments that have millions of state-action pairs.
Deep neural networks (DNN) possess the ability to learn complex non-linear functions and can be used as function approximators. Specifically, for the case of reinforcement learning, trained neural networks can be used as a policy to approximate the best action to take, given a state without needing an explicit value table.
Deep reinforcement algorithm is the combination of RL with DNN that allows a model to learn complex state-action associations using distal reward signals. Unlike computer vision or natural language processing, deep RL models cannot be trained by batch due to the alternating processes of policy evaluation and update. For this, deep RL can be deployed as a CPU only process. However, if the model requires updating millions of parameters, the processing time for policy update increases drastically. At the same time, the time taken to load and retrieve the tensors onto the GPU for training becomes significant if the policy evaluation and update phases are relatively fast. This is usually the case for smaller models with hundreds to thousands of parameters or during DQN whereby a batch of episodic memories are trained individually.
Current state of the art algorithms include Deep Q Networks (DQN) and Advantage Actor Critic (A2C) whereby the model is usually written in Tensorflow or PyTorch with GPU support while the rest of the environment and training script is written for CPU. Due to this implementation, the policy evaluation phase occurs in the CPU while the policy update phase – where the model weights are updated – occur in the CPU or GPU.
For the purpose of this report, we test both cases where the computation for deep RL occurs only in the CPU or toggles between the CPU and GPU. The results show the difference in processing time when training deep learning models using RL using both CPU and with GPU with different network size.
Method
The RL task is for an agent to learn to navigate to two cue-reward locations in an open field maze. The states in the maze is continuous. The model used is a simple recurrent neural network with varying hidden units. The state information of the agent location is passed to the model using a convolutional neural network of 5 filters of size 2. The cue and past action are passed to the RNN as a one hot vector together with the reward obtained in the past timestep. The model treats the maze as a discrete setup with each millisecond as 1 timestep. Each trial is 120 seconds and the trial is terminated once the max time is reached while the model acquires as much reward as possible. The model is trained using Advantage Actor Critic (A2C) algorithm.
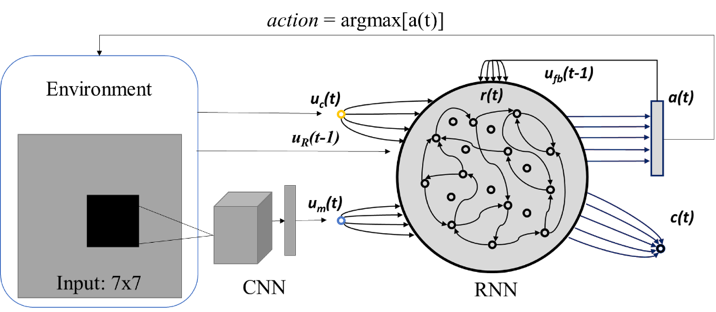
Fig 1. Model and Environment setup for deep reinforcement learning. The environment provides three information – the current location of the agent in a maze, current cue for the respective reward location and the reward obtained in the previous timestep. The policy network is a recurrent neural network of varying size trained by Advantage Actor Critic (A2C).
Performance comparison
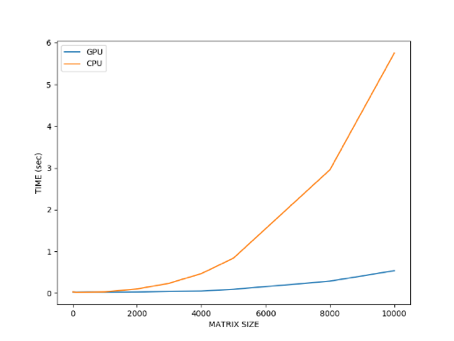
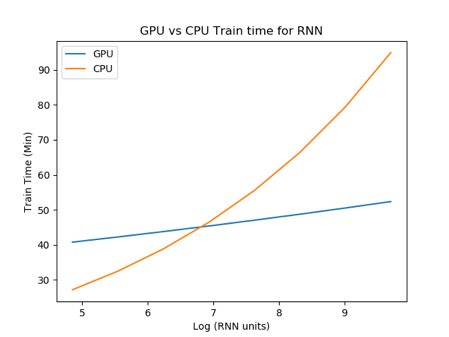
Fig 2. Performance comparison of CPU and GPU based computations A) Time taken to perform simple matrix multiplication of different sizes. Both show monotonic increase in time of computation while the CPU computation increases exponentially after matrix size of 2000. B) Time taken (minutes) for model in Fig 1. to learn the task in 500 trials by A2C.
Performing simple matrix multiplications (of size less than 2000) seem to be of equivalent speed for both CPU and GPU in Fig 2A. However, when the matrix size increases beyond 2000, the time taken for the multiplication increases exponentially for CPUs while that of GPU increases only slightly.
When we run a deep RL experiment, the CPU shows a shorter processing time compared to the GPU when the number of RNN hidden units is between 128 to 1024 (shown with a log x axis scale in Fig 2B). This could be due to the time taken when loading and unloading the tensors between the CPU and the GPU.
When the number of hidden units increases beyond 1024, the CPU processing time supersedes the GPU and increases exponentially. However, the processing time with the GPU seems to increase linearly. This could be due to the number of parameters that can be tuned in parallel by the GPU while the CPU struggles to perform these large matrix multiplications as in Fig 2A.
Learning points, Recommendations
This simple experiment demonstrates that using GPUs to train deep RL models may not necessarily lead to shorter processing times. Most work involving RNNs for deep RLs use 64 to 512 hidden units. When training these models, it is recommended to use a CPU server such as the parallel 20 instead of GPU servers such as Volta. This will free up the GPU servers for other deep learning experiments that have batch training or have millions of parameters to tune.
Based on this experiment, it is recommended for users to run a few trials to determine whether a CPU only process provides a shorter training time compared to a GPU system. To obtain nuanced information, a log file that states where the system bottlenecks are should be generated.
This is specifically in terms of the time taken:
- during policy evaluation where the environment is rendered based on the action taken by the agent
- During policy update where the model parameters are tuned
- When the tensors are loaded and unloaded from the GPU
Based on this information, the experiment script can be edited to minimise the bottlenecks and allow the user to determine whether to use the parallel20 CPU system or the Volta GPU system to train deep RL models.
Conclusion
Parallel distributed computing resources such as GPUs have contributed to the popularity of using deep learning models. Understanding how computations occur will allow researchers and innovators to optimise their workflow and processing times. In the case of deep RL, researchers stick to smaller models or use recurrent networks to reduce the number of trainable parameters.
New algorithms such as the Asynchronous Advantage Actor Critic (A3C) parallelises the environment based on the number of CPU cores available to decrease overall training time. Perhaps there could be more work to integrate the strengths of both CPUs and GPUs and this could accelerate more interest in deep RL, just as how DL has gained its popularity. The other route would be to understand how our neural circuitry is able to perform parallel distributed computing while performing a myriad of sequential computations.
Neuromorphic chips or quantum computers could play a role in the next transcendence, however we need intelligent algorithms and architectures that model after brain dynamics and plasticity in order to truly be a game changer.
