Get Better Performance for Your Machine Learning
Wang Junhong, Research Computing, NUS Information Technology
Abstract
MLPerf benchmark was carried out on one of the central shared 4-GPU servers with different configurations on the number of GPUs and the input batch sizes. The computing performance and the different configurations are compared. Good performance is demonstrated by the GPU server when running the MLPerf case on all 4 GPUs. Users are recommended to run a quick benchmark to find out the right GPU configuration and the right batch size to achieve optimal performance.
Background
Motivated in part by the Standard Performance Evaluation Consortium (SPEC) benchmark for general-purpose computing (CPU in general), MLPerf benchmark is developed to build fair and useful benchmarks that provide unbiased evaluations of training and inference performance for hardware, software, and services—all conducted under prescribed conditions. MLPerf benchmark is widely accepted and adopted benchmark suite by the Artificial Intelligence (AI) community.
MLPerf benchmark was carried out on a 4-GPU server with different configurations on 1) number of GPUs, and 2) input batch size. The relationship of performance and the different configurations will be compared and discussed.
Benchmark Environment and Configuration
The benchmark case is carried out on one of the central shared 4-GPU servers, which are available to all NUS researchers. The 4-GPU server is equipped with 4 Nvidia Tesla V100-32GB cards and fast IO speed SSD-based storage.
MLPerf Benchmark Suite
The MLPerf Benchmark suite includes:
- Training set: 1000 categories and 1.2 million images
- Validation & test: 100 categories and 150,00 images
Benchmark Configuration
On the 4-GPU server, the benchmark tests were carried out on 1 GPU, 2 GPUs and 4 GPUs for comparison.
The input batch size shall be chosen in order to fully utilize the underlying computational resources such as GPU memory or disk IO bandwidth, to achieve better performance. Considering the existing GPU server’s GPU memory resource, the benchmark tests were carried out with the following batch sizes:
|
Number of GPUs in Use |
Batch size |
|
1-GPU |
64, 128, 256 |
|
2-GPU |
64, 128, 256, 512 |
|
4-GPU |
64, 128, 256, 512, 1024 |
Benchmark Results
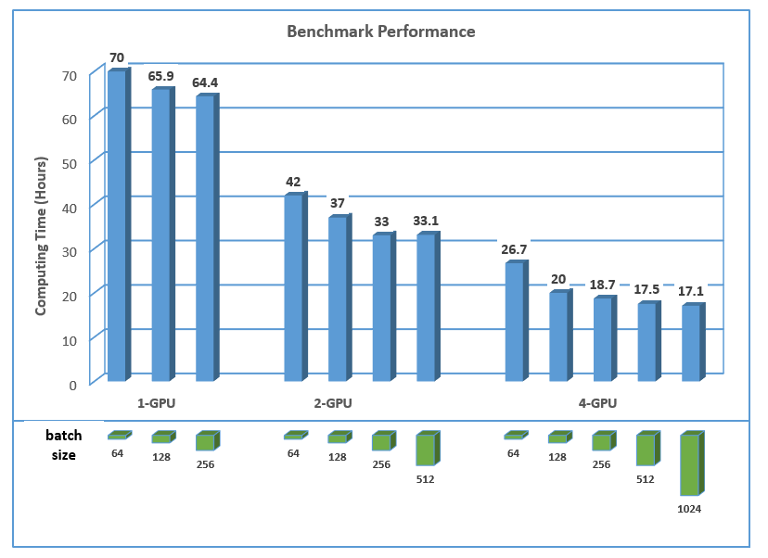
The computing time taken for each of the benchmark cases is plotted in the graph below. From the results, it is observed that:
- The computing time is shortened significantly when running the benchmark case on 2-GPU and 4-GPU, with about 1.7X and 3.3X faster approximately.
- In general, the computing time is shortened by about 7% when the batch size is doubled on all the 3 GPU configurations.
- The performance improvement is very minor or even worse when the batch size per GPU is increased to 256.
Conclusion and Recommendation
From this MLPerf benchmark test on the 4-GPU server, the GPU server demonstrates good performance when using multiple GPUs. The input batch size affects the performance marginally and reaches optimal performance at 512 per GPU, which may fully use the GPU resources.
The data set of this MLPerf benchmark is quite sizable. To enjoy the better or best performance on running your own ML and DL on the GPU server, you are recommended to do a quick benchmark by comparing the performance among different GPU configurations, different batch sizes and others. If resources permit, you can consider to run your machine learning (ML) and deep learning (DL) with more GPUs and sizable batch size to get optimal performance.
