Data Manipulation and More with the Command Line
by Ku Wee Kiat, Research Computing, NUS Information Technology
Ever needed to have a directory of files renamed to a certain format? Extract lines with certain keywords from log files? Even create csv files from semi-structured logs?
There is no need to bust out the custom python or R scripts or install any software when most simple tasks can be solved at a much faster speed using Bash tools.
 The Basics
The Basics
Some Keywords and Symbols
- ● stdout
- ○ Standard Output
- ○ default file descriptor where a process can write output.
- ● stdin
- ○ Standard Input
- ○ default file descriptor where a process can read input.
- ● stderr
- ○ Standard Error
- ○ default file descriptor where a process can write error output
- ● |
- ○ Pipes
- ○ a pipe is a special file that connects the output of one process to the input of another process
- ○ e.g.: cat file1.txt | grep keyword
- ◼ Find lines with “keyword” in file1.txt
- ● >
- ○ redirect, write
- ○ e.g.: cat file1.txt > file2.txt
- ◼ Overwrite the contents of file2 with file1
- ● >>
- ○ redirect, append
- ○ e.g.: cat file1.txt >> file2.txt
- ◼ Append the contents of file1 to file2
- ● $variableName
- ○ Access bash variable by adding ‘$’ in front of variable name
- ○ Assign variable in bash:
- ◼ variableName=”some_string”
- ● man tool_name
- ○ Manual of a bash tool
- ○ e.g.: man ls
- ◼ Prints Directory listing tool (ls) manual to terminal
Commands & Tools
ls – list directory contents

cat – concatenate files and print on the standard output
For concatenating the contents of one file to another:
cat file1.txt >> file2.txt |
For overwriting the contents of one file with another
cat file1.txt > file2.txt |
For copying the contents of multiple files (train1.txt, train2.txt, train3.txt )to a single file (mega_train.txt)
cat train*.txt >> mega_train.txt |
head – output the first part of files
use -n 5 to read just 5 lines. Replace 5 with any other number.
Use this to peek at large files you do not want to open as a whole.

tail – output the last part of files
use -n 5 to read just 5 lines. Replace 5 with any other number.

grep, egrep, fgrep, rgrep – print lines matching a pattern
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] -e PATTERN ... [FILE...]
grep [OPTIONS] -f FILE ... [FILE...]
 grep can also be used with regular expressions:
grep can also be used with regular expressions:
grep -E ‘[0-9]’ |
diff – compare files line by line
# Remove the first line from our dataset |
find - search for files in a directory hierarchy
# Find all directories named src |
Chaining Commands with Pipes
sed – stream editor for filtering and transforming text
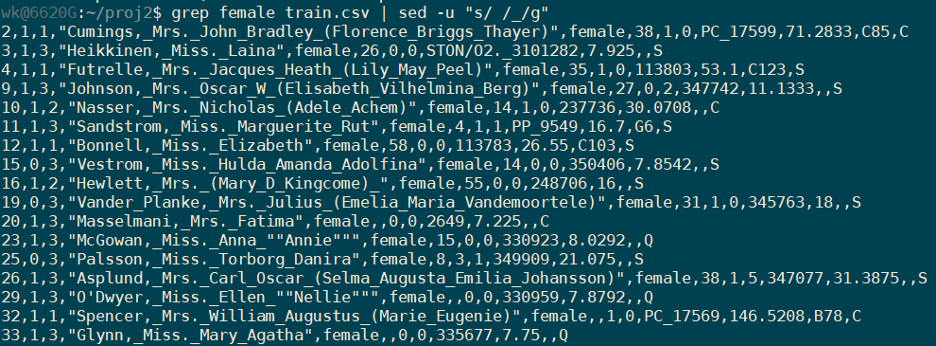
Replace space with _ using regular expressions
wc – print newline, word, and byte counts for each file
use -l option for counting lines

We can combine a few commands to accomplish a task.
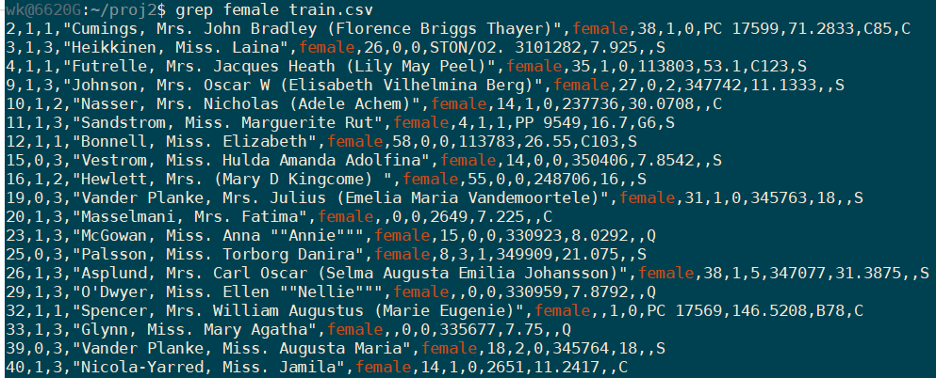
For example, counting the number of lines in train.csv dataset that are females.

And for males:

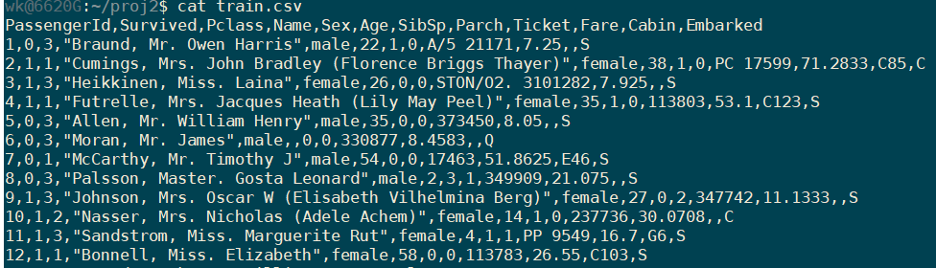
The features available in the dataset are as shown:

Let’s say we just need the PassengerId and Name of the Passenger,
we can use the awk tool.
gawk/awk – pattern scanning and processing language
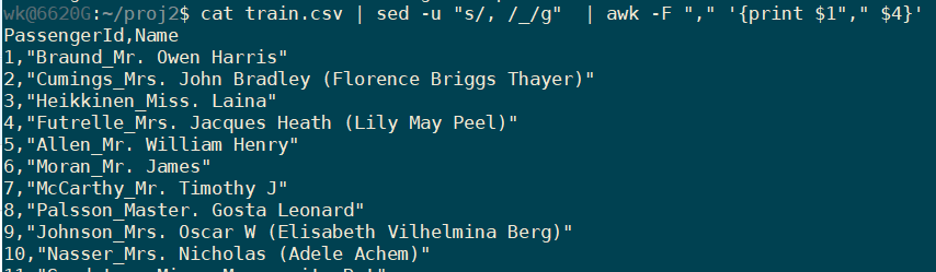
and if you need to save the output to a file, you can use “>” or “>>”.
For example:
cat train.csv | sed -u "s/, /_/g" | awk -F "," '{print $1"," $4}' >> output.txt
|
We are using sed in the above example to replace the commas within names to and underscore as we specified awk to delimit by “,”, this might split names if we do not get rid of commas in them.
If we want to get rid of the first line which is the column names and just keep the data:
Use: sed nd where n is the nth line to delete

Other usage:
Delete a range of lines: sed n,md
Multiple deletes: sed 1;3;n,md
sort – sort lines of text files
Using sort we can sort column values as well
Sorting my names which is the 2nd column, columns separated by “,”:

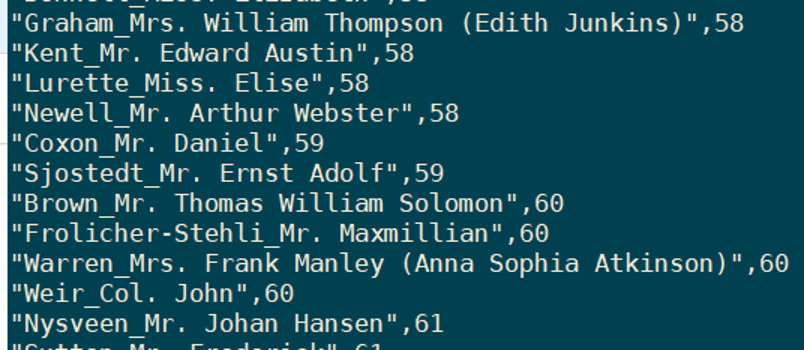
Sort by age display only name and age columns:
cat train.csv | sed -u "s/, /_/g" | awk -F "," '{print $4"," $6}' | sed 1d | grep -E '[0-9]' | sort --field-separator="," -k2 -g
|
uniq – report or omit repeated lines
If we want to get a list of all possible ages, we can use uniq:
cat train.csv | sed -u "s/, /_/g" | awk -F "," '{print $6}' | sed 1d | grep -E '[0-9]' | sort --field-separator="," -k2 -g | uniq | sort -g
|
 cut – remove sections from each line of files
cut – remove sections from each line of files
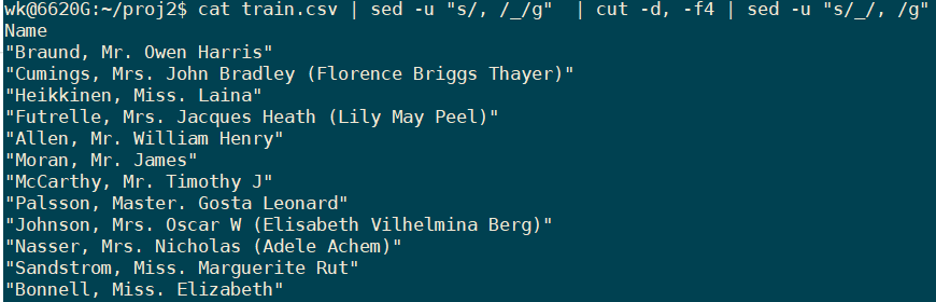
We can use cut tools to extract column(s) as well instead of awk
In the below example, we use cut to extract the name column, but before that we must substitute the commas in the name column with underscores as cut depends on commas as the delimiter. After substitution, we pipe the output into the cut command to retrieve only the name column and then reverse the substitution we did earlier using sed.
If you want to ensure there’s no duplicates, you can always pipe the out from the above command into sort and then uniq to get unique values.
Look out for subsequent installments for more tips and tricks.
