Anomaly Detection: A Machine Learning Use Case – Part 2
Kuang Hao, Research Computing, NUS IT
Anomaly detection is widely used in behavioural analysis to determine the types of anomalies occurring in a given data set. In domains such as fraud detection, intrusion detection, fault detection and system health monitoring, anomaly detection helps to avoid system damages and potential financial breaches.

Following up on our last article posted in 2020, we will introduce an additional complex machine learning algorithm in anomaly detection and demonstrate how we can do that on our HPC cluster in this article. The demonstration notebook used in this article can be found here.
AutoEncoder
An autoencoder is a special type of neural network that copies the input values to the output values. It does not require the target variable like the conventional Y; thus, it is categorised as unsupervised learning. In an autoencoder, we are not interested in the output layer, instead we are interested in the hidden core layer. If the number of neurons in the hidden layers is less than that of the input layers, the hidden layers will extract the essential information of the input values. This condition forces the hidden layers to learn the most patterns of the data and ignore the “noises”. So, in an autoencoder model, the hidden layers must have fewer dimensions than those of the input or output layers. If the number of neurons in the hidden layers is more than those of the input layers, the neural network will be given too much capacity to learn the data. In an extreme case, it could just simply copy the input to the output values, including noises, without extracting any essential information. [1]
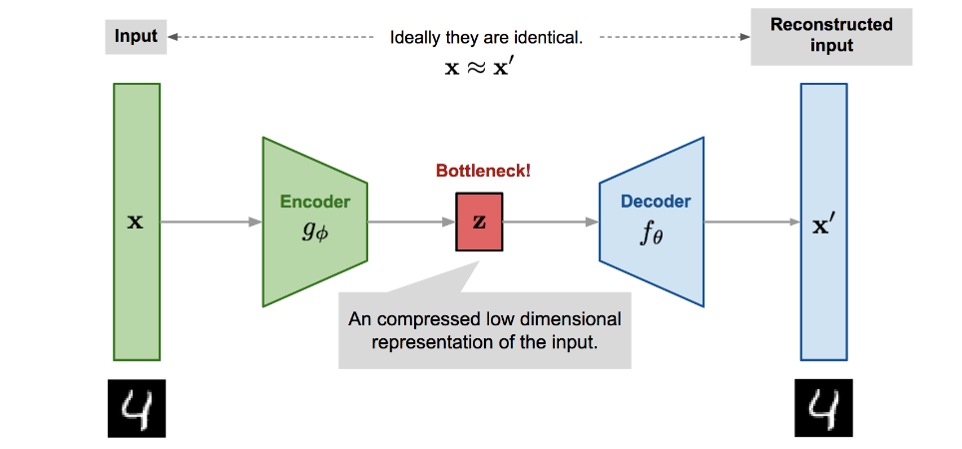
The early application of autoencoders is dimensionality reduction. A milestone paper by Geoffrey Hinton (2006) showed a trained autoencoder yielding a smaller error compared to the first 30 principal components of a PCA and a better separation of the clusters. Autoencoders also have wide applications in computer vision and image editing. In image colouring, autoencoders are used to convert a black-and-white image to a coloured image. In image noise reduction, autoencoders are used to remove noises.

In the context of anomaly detection, the autoencoder techniques can perform non-linear transformations with their non-linear activation function and multiple layers. It is more efficient to train several layers with an autoencoder, rather than training one huge transformation with PCA. The autoencoder techniques thus show their merits when the data problems are complex and non-linear in nature.
Demo
For demonstration, we use this dataset from Kaggle: Credit Card Fraud Detection. This dataset contains credit card transactions that occurred in two days, where there are 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, where the positive class (frauds) account for 0.172% of all transactions and, therefore, classic machine learning classification is out of the question. To protect sensitive personal information, it contains only numerical input variables – the result of a PCA transformation.
The idea behind our anomaly detection model is simple: due to the bottleneck architecture of the autoencoder, it is forced to learn a condensed representation from which to reproduce the original input. We feed it only the benign transactions, in which way it will learn to reproduce with high fidelity. Consequently, if a fraud transaction is sufficiently distinct from normal transactions, the autoencoder will have trouble reproducing it with its learned weights, and the subsequent reconstruction loss will be high. Thus, anything above a specific threshold will be flagged as an anomaly. The structure of our model is shown below:
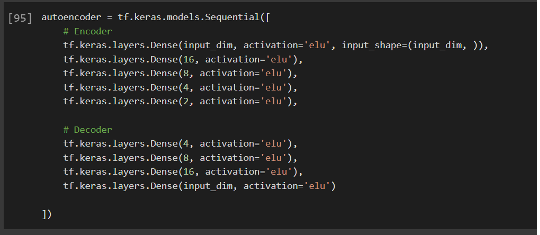
For test data, we apply the transformation pipeline to our test set and then pass the data through the trained autoencoder.

The next step is thresholding, for which our model is trained in an unsupervised manner. From this step, the rest is no different from our last introduction.
As an alternative, we can also use a Python package for outlier detection: PyOD. It has a built-in autoencoder, with the backend of both Pytorch and Keras.
Conclusion
This article aims to introduce common machine learning approaches in anomaly detection. In part 1 of this introduction, we have covered several machine learning algorithms that are applicable in anomaly detection: PCA, Isolation Forest, One-Class SVM, RNN and AutoEncoders. There is no rule of thumb in choosing the correct algorithm as data features vary drastically, especially in the domain of anomaly detection. But by following this article, you would be able to set up quickly and test each one as your candidate models.
Python packages used in this article (Keras, PyOD) can be easily installed on HPC clusters. Contact us if you have any issues using our HPC resources, via A.S.K.
Reference
- TowardsDataScience. (2010). Anomaly Detection with Autoencoders Made Easy. [online] Available at: https://towardsdatascience.com/anomaly-detection-with-autoencoder-b4cdce4866a6
