AI-Aided Tools for Research
Ku Wee Kiat, Research Computing, NUS Information Technology
Do you ever have the need to extract text from article scans, or data from invoices/receipts?
Are you dealing with small tabular datasets with sensitive information that requires more data?
Do you have a low-resolution or poor-quality image but want something of a higher quality or resolution?
In this article, we will look at some Python-based AI-aided tools and libraries that might be useful for your research:
- Data Extraction
- Data Generation
- Data Enhancement
Data Extraction Tools
 |
 |
 |
 |
Scan Document -> Scanned Document Image -> OCR -> Text Document
If you are someone who works with a lot of analogue medium or have a need to digitize data for further processing in your research or task, the Optical Character Recognition (OCR) tools will be your lifesavers. General OCR tools works best at extracting text in simple/clear fonts from a clear, straight, high quality image. However, high quality images may be rare in most cases. Often you may be dealing with hastily shot photos of receipts or documents, or photos that are not taken in an ideal environment. And at other times, you might want to extract textual information from drawings, logos, signage and other complex images. For such cases, general OCR tools do not perform well.
MMOCR
Introducing the MMOCR tool by OpenMMLab (https://mmocr.readthedocs.io/en/latest/).
MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the corresponding downstream tasks including key information extraction.
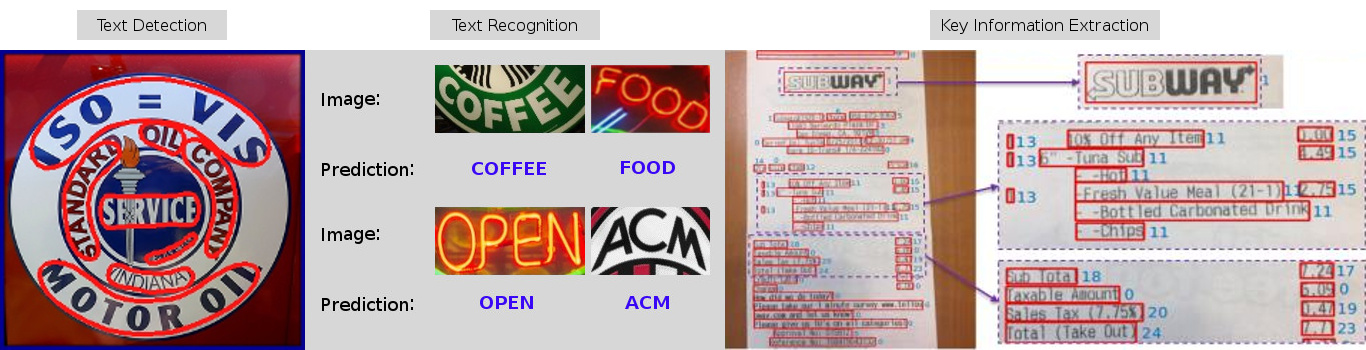
As shown in the image above, the MMOCR tool was able to detect and extract text from logos, neon signage and receipts. Even if the text is bent (see first image from the left), odd (see 2nd image from the left) or even have mixed fonts and layout (see images of receipt).
Features:
- Comprehensive Pipeline
- The toolbox supports not only text detection and recognition, but also their downstream tasks such as key information extraction.
- Multiple Models
- The toolbox supports a wide variety of state-of-the-art models for text detection, text recognition and key information extraction.
Some definitions:
• Text Detection: detect text in an image, provides coordinates to segment or draw a box around detected text in an image.
 Image 1: Text with bounds in green (Text Detection only)
Image 1: Text with bounds in green (Text Detection only)
• Text Recognition: converts detected text into digitised form. E.g.: Given an image of a Starbucks logo and detected coordinates for the regions where “Starbucks” and “COFFEE” are located -> run text recognition -> Get “Starbucks” when given “Starbucks” region of image, get ”COFFEE” from “COFFEE” region of image.
 Image 2: Text Recognition only
Image 2: Text Recognition only
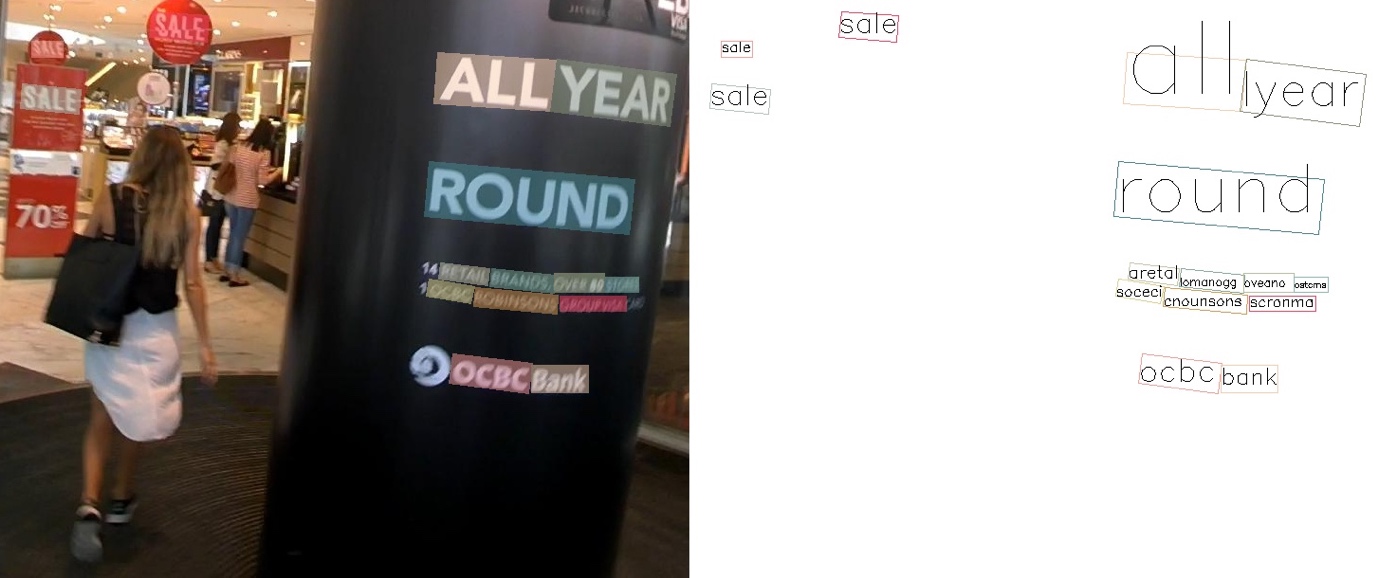 Image 3: Text Detection followed by Text Recognition
Image 3: Text Detection followed by Text Recognition
• Key Information Extraction: Identify type of key information of text.
 Image 4: Key Information labelled for each detected and recognised text
Image 4: Key Information labelled for each detected and recognised text
Above examples extracted from: https://mmocr.readthedocs.io/en/latest/demo.html#example-1-text-detection
MMOCR provides a variety of models which are trained to tackle different image situations. For example, there are models that are best at detecting curved texts or arbitrary-shaped text from images, while there are text recognition models which are better at detecting irregular or arbitrary-shaped text.
Layout Parser
Layout Parser (https://layout-parser.github.io/)
From the website:
Layout Analysis – in 4 Lines of Code
Transform document image analysis pipelines with the full power of Deep Learning.
Layout Parser’s speciality is in Deep Learning Based Document Image Analysis. Unlike MMOCR, it is not for text detection in a scene or logo.
Accurate Layout Detection with a Simple and Clean Interface
Utilising deep learning models, Layout Parser enables extracting complicated document structures using only several lines of code. This method is also more robust and generalizable as no sophisticated rules are involved in this process.

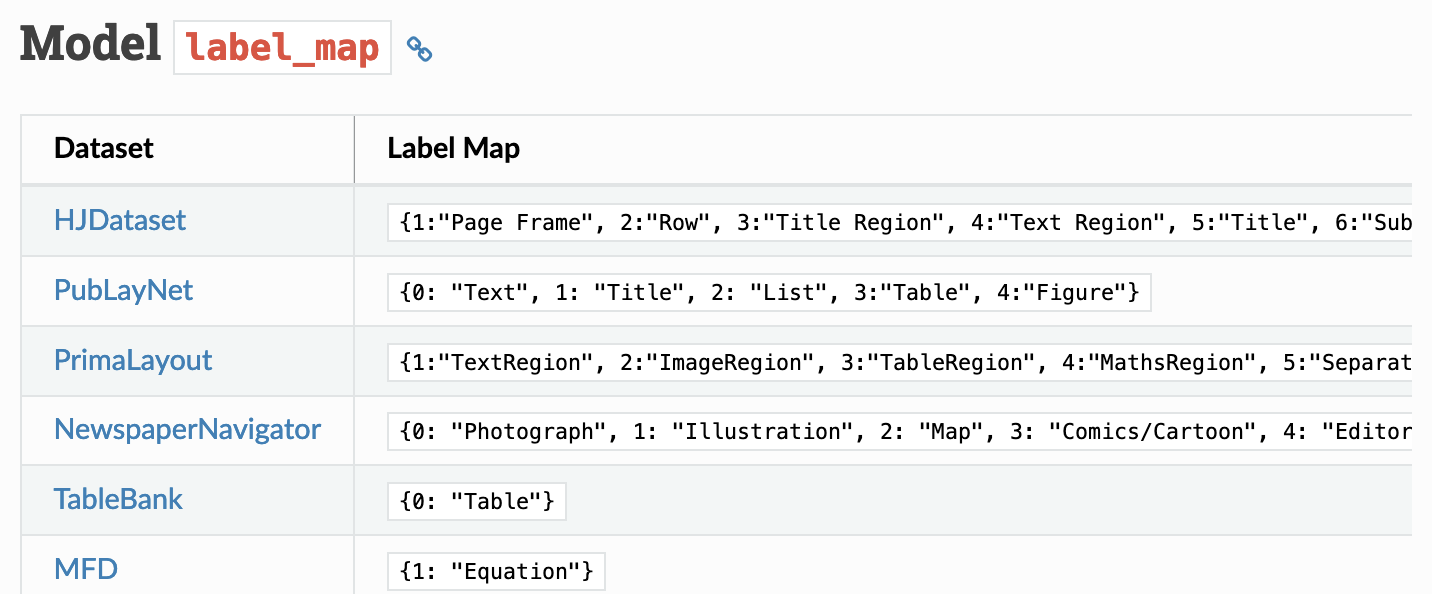
You would need to choose the deep learning model to use from the Model Catalogue provided in Layout Parser’s documentation (see below). Some models excel at detecting layout of newspaper or newspaper like images while some are better at detecting and extracting information from a table or academic publication. Currently there are 9 models trained on 5 diverse datasets, and they can be loaded via a unified interface.

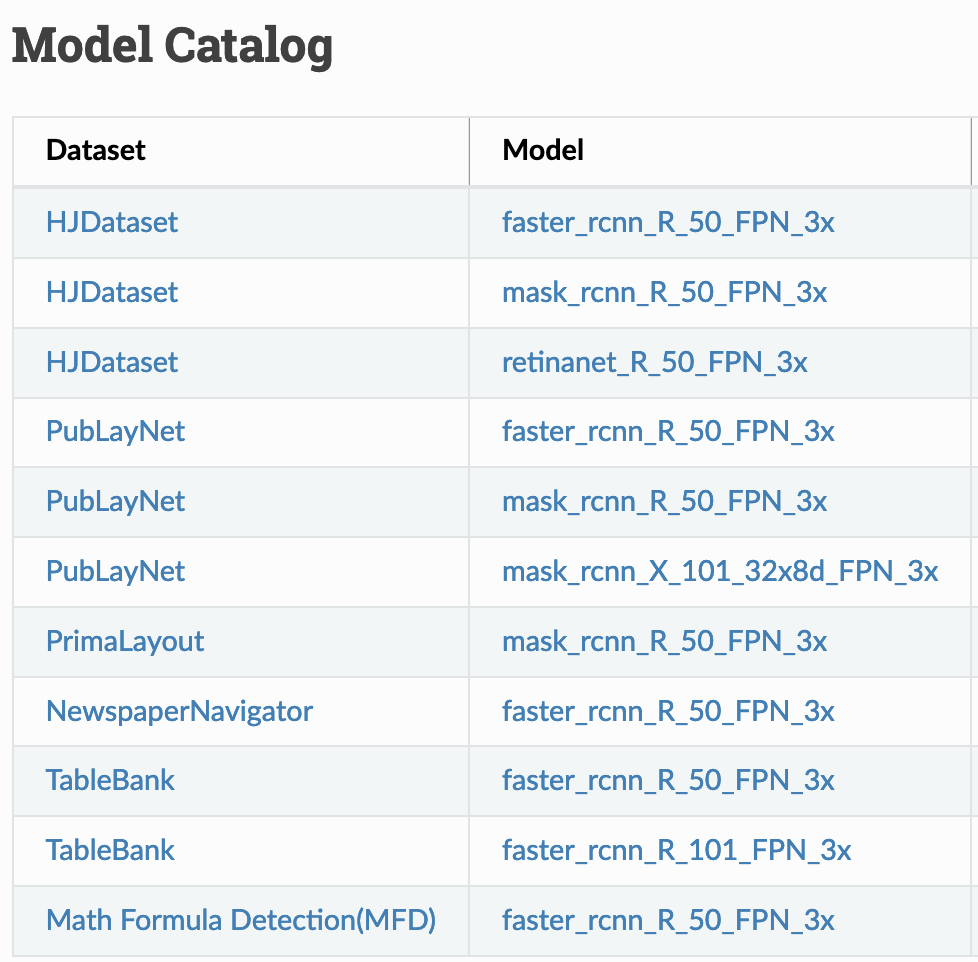 If you want to parse newspaper layouts, you can use the NewspaperNavigator model. TableBank is useful for extracting data from documents with tables.
If you want to parse newspaper layouts, you can use the NewspaperNavigator model. TableBank is useful for extracting data from documents with tables.
Models trained on the HJDataset, which is a large dataset of Historical Japanese Documents with Complex Layouts (https://dell-research-harvard.github.io/HJDataset/), will be proficient on documents that are similar to what it has been trained on.
Layout Parser outputs the following data structure for its detections.
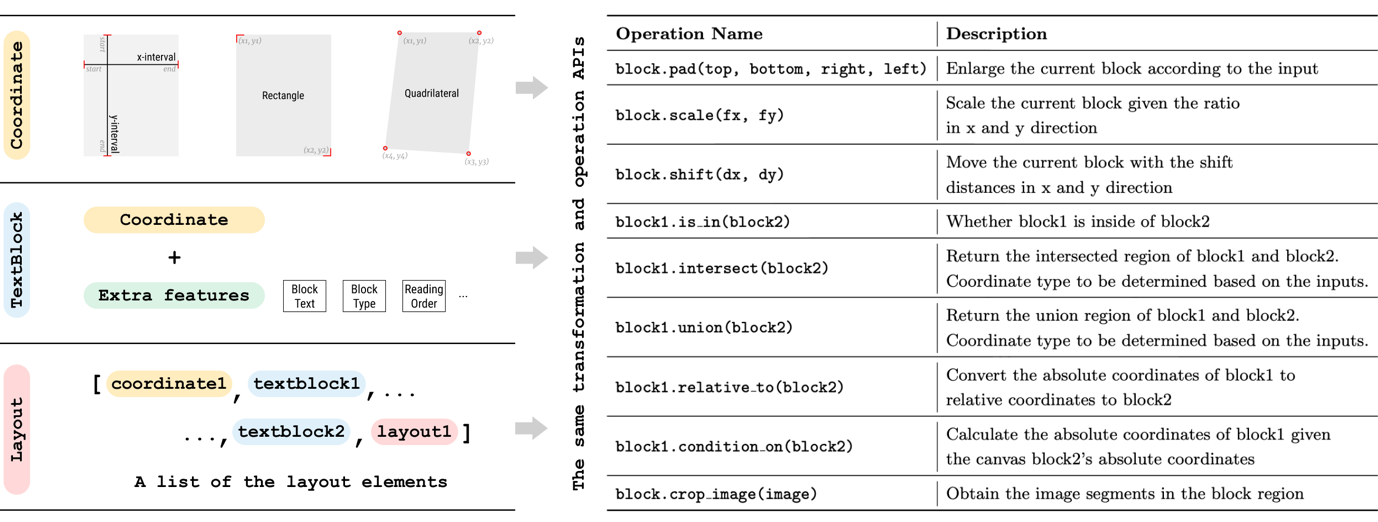
You can visualise the detection as well using built-in functions.

Additional Example:
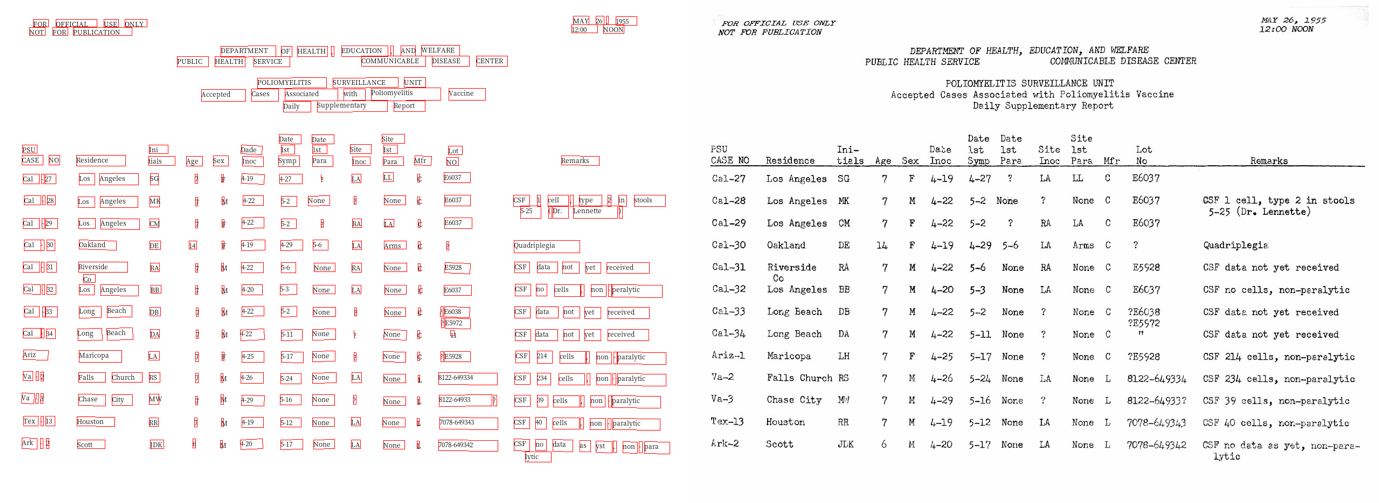
For text recognition, Layout Parser utilises Google Cloud Vision’s OCR API or Tesseract OCR. With some effort, you might be able to integrate MMOCR with Layout Parser for more complex text detection and text recognition.
Data Generation Tools
Now let’s take a look at a group of tools that generates data. Synthetic data are most useful when you have a lack of data to train your models, or when you have a sensitive dataset.
Synthetic Data Vault – SDV
The first tool in this category is the Synthetic Data Vault – SDV. The Synthetic Data Vault (SDV) is a Synthetic Data Generation ecosystem of libraries that allows users to easily learn single-table, multi-table and timeseries datasets to later generate new Synthetic Data that has the same format and statistical properties as the original dataset.
Synthetic data can then be used to supplement, augment and in some cases, replace real data when training Machine Learning models. Additionally, it enables the testing of Machine Learning or other data dependent software systems without the risk of exposure that comes with data disclosure.
Current functionality and features:
- Synthetic data generators for single table datasets with the following features:
- Using Copulas and Deep Learning based models.
- Handling of multiple data types and missing data with minimum user input.
- Support for pre-defined and custom constraints and data validation.
- Synthetic data generators for complex, multi-table, relational datasets with the following features:
- Definition of entire multi-table datasets metadata with a custom and flexible JSON schema.
- Using Copulas and recursive modelling techniques.
- Synthetic data generators for multi-type, multi-variate timeseries datasets with the following features:
- Using statistical, Autoregressive and Deep Learning models.
- Conditional sampling based on contextual attributes.
- Metrics for Synthetic Data Evaluation, including:
- An easy to use Evaluation Framework to evaluate the quality of your synthetic data with a single line of code.
- Metrics for multiple data modalities, including Single Table Metrics and Multi Table Metrics.
For some hands-on with SDV check out this link.
Gretel Synthetics
With greater concern and awareness about privacy, there is a need for a solution to train ML models on handling sensitive data in a secure and privacy aware way. The tagline for Gretel Synthetics is: “Differentially private learning to create fake, synthetic datasets with enhanced privacy guarantees.”
There are two modes for Gretel Synthetics:
Simple Mode
The simple mode will train line-per-line on an input file of text. When generating data, the generator will yield a custom object that can be used a variety of different ways based on your use case. This notebook demonstrates this mode.
DataFrame Mode
This library supports CSV / DataFrames natively using the DataFrame “batch” mode. This module provided a wrapper around our simple mode that is geared for working with tabular data. Additionally, it is capable of handling a high number of columns by breaking the input DataFrame up into “batches” of columns and training a model on each batch. This notebook shows an overview of using this library with DataFrames natively.
There is also an option to use the model that provide Differential Privacy. The example notebook can be found here.
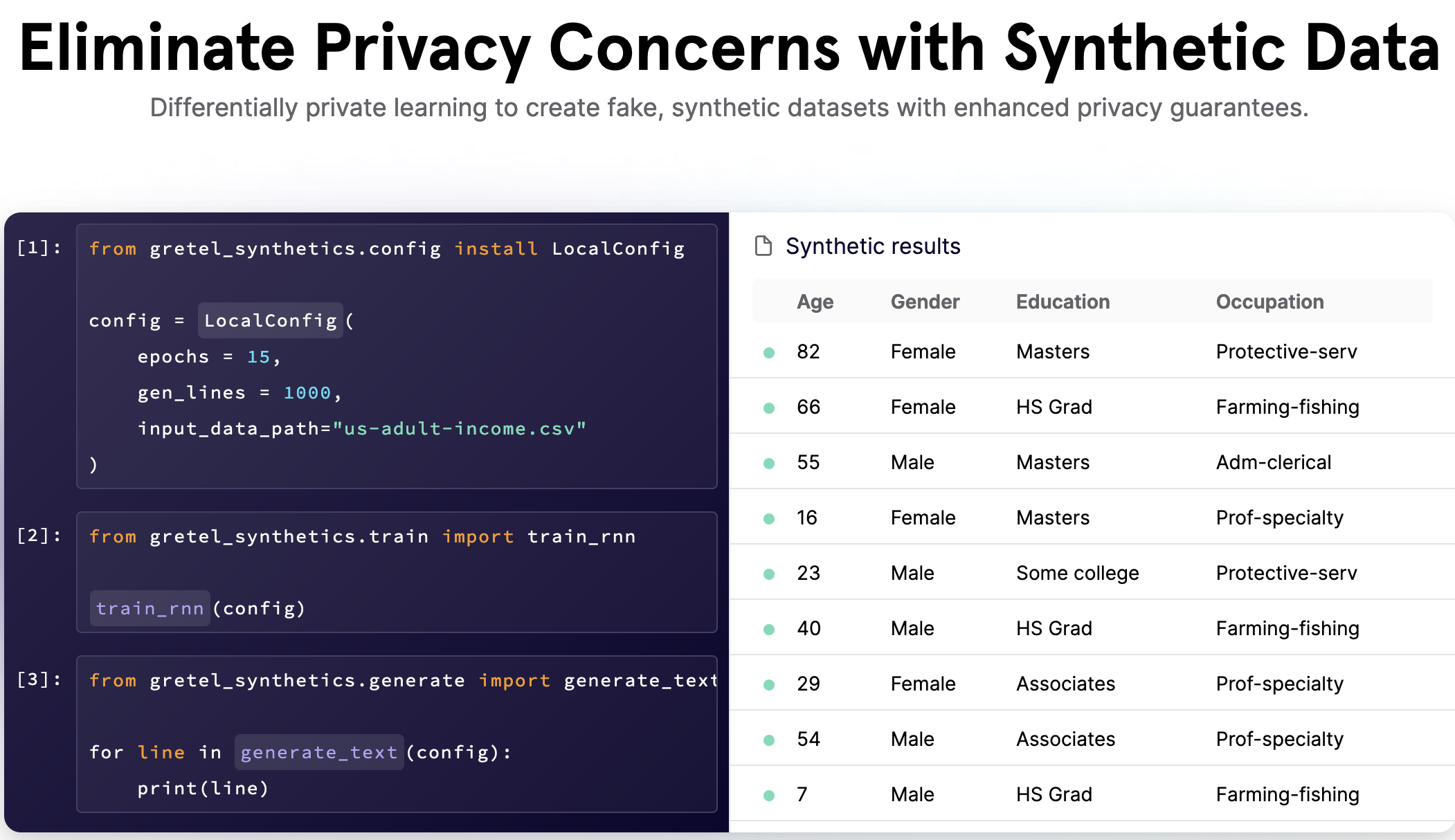
Data Enhancement Tools
Besides extracting or generating data, we have tools that enhances data as well.
We will just cover one tool in this article, Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data. Real-ESRGAN is a tool for image super resolution, basically increasing the resolution of an image. The sample images from this model seems to have a perceivable increase in image quality. This makes it useful as a tool for enhancing images.
Some examples from the authors:

The sample model provided by the authors are trained to upsample by 4 times. According to the authors, Real-ESRGAN may still fail in some cases as the real-world degradations are too complex. Moreover, it may not perform so well on human faces, text, etc, which will be optimized later.
You can check out the demo on Colab here.
These are the 3 groups of AI-Aided tools that we will be covering today which you might want to utilise for your research/project.
If you have any other suggestions for AI-Aided tools, do let us know at dataengineering@nus.edu.sg. If you’d like to showcase your project that utilised AI-Aided Tools, do let us know as well.
Data Extraction Tools
Data Generation Tools
Data Enhancement Tools
