Acceleration of Data Pre-processing
By Kuang Hao, HPC Specialist, Research Computing, NUS Information Technology
As the first step in machine learning’s pipeline, the importance of data pre-processing (DP) should never be neglected. For researchers and data science learners, thanks to our open source community and all the machine learning enthusiasts, there are all the clean and generalized datasets online for research and studying. But real-life data is almost never well-organized, that’s why hard work and time should be devoted to the DP pipeline.
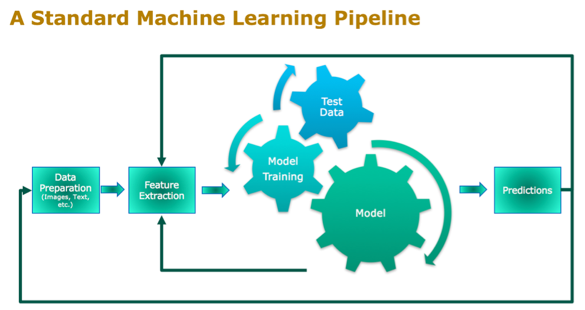
For text dataset, from messy log data retrieved from servers to unstructured daily comments and messages scraped from the internet, to parse, clean and vectorize the huge amount of data can be a challenging task. This article aims to explore several ways to optimize the DP pipeline using our HPC resources.
Multi-core acceleration
First and foremost, DP is a traditional CPU-bound task. To accelerate the process, it’s intuitive to utilize multiple CPUs.
For deep learning users, if we are using Tensorflow or Keras, “tf.data” API can be implemented to build a flexible and efficient input pipeline. It uses multicore by default and optimizes the ETL (Extract, Transform and Load) process to reduce CPU idling time, and datasets can be created from Numpy arrays, CSVs, tensors and text files directly. [1]

However, for other ML/DL cases or data mining tasks, we might have trouble searching for available APIs to automatically optimize our DP pipeline. For instance, popular NLP packages like “NLTK” and “Spacy”, only utilize single core during DP by default. So it’s important to learn and know how to implement the optimization by ourselves.
When it comes to python, GIL (Global Interpreter Lock), who prevents multiple threads accessing the same python objects, is always controversial among developers. Though thread-safe, it prevents multithreaded CPython programs from taking full advantage of multiprocessors.
To utilize multiple cores, python package “multiprocessing” is needed. More specifically, “concurrent.futures” is a high-level interface which provides a wrapper around “multiprocessing.pool”, and can be easily introduced to our DP pipeline. “torch.multiprocessing” is another wrapper that supports shared memory of tensors. Note that on Windows, remember to import “__main__”, since there is no system call “fork” on Windows, “__main__” is needed to distinguish child processes from parent ones. Below is the sample code for using “concurrent.futures”.
# Multi-core acceleration
# Adapted from: https://stackoverflow.com/questions/42941584/
import concurrent.futures
from collections import deque
# multi-thread for IO tasks
TPExecutor = concurrent.futures.ThreadPoolExecutor
# multi-process for CPU tasks
PPExecutor = concurrent.futures.ProcessPoolExecutor
def get_file(path):
# IO task: read data
with open(path) as f:
data = f.read()
return data
def process_large_file(s):
# CPU task: process data
return sum(ord(c) for c in s)
# Prepare lists of items to preocess, in this sample: multiple files
files = [filename0, filename1, filename2, filename3, filename4,
filename5, filename6, filename7, filename8, filename9]
results = []
completed_futures = collections.deque()
def callback(future, completed=completed_futures):
completed.append(future)
# For Windows, below sections should be included in "__main__"
with TPExecutor(max_workers = 4) as thread_pool_executor:
data_futures = [thread_pool_executor.submit(get_file, path) for path in files]
with PPExecutor() as process_pool_executor:
for data_future in concurrent.futures.as_completed(data_futures):
future = process_pool_executor.submit(process_large_file, data_future.result())
future.add_done_callback(callback)
# collect any job that has finished
while completed_futures:
results.append(completed_futures.pop().result())
Though “multiprocessing” functions well, it can be tricky for implementation. Incorrect scripts might actually run slower than the basic single-thread way, and even exhaust system’s resources when entry point is unprotected carelessly. To avoid the danger, we can also make use of “Dask”.
Dask allows us to use abstractions of Numpy arrays and Pandas dataframes to run in parallel using multicore processing, and can run on distributed clusters [2]. Dask also provides scalable “Scikit-Learn” to scale machine learning parallelly.
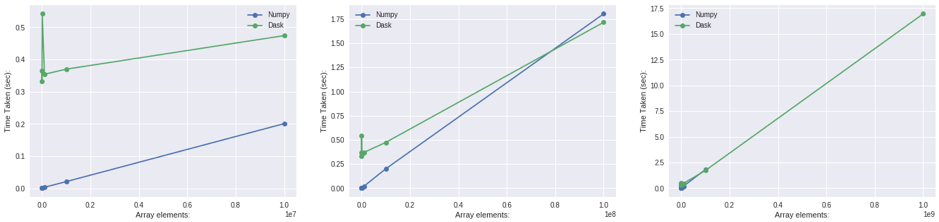
The figure above (fig1) shows that when dealing with smaller amount of data (< 1e7), Numpy is faster. But Dask is taking over around 0.8e8 records with the amount of data growing (fig2). And for data larger than memory, Numpy is not capable of processing it (fig3). In my opinion, it’s by far the simplest way for parallel DP with Python, and it can deal with dataset that cannot fit in memory easily. [3]
GPU acceleration
RAPIDS is a suite of software libraries designed for accelerating Data Science by leveraging GPUs. It uses low-level CUDA code for fast, GPU-optimized implementations of algorithms while still having a friendly Python layer on top. More specifically, we make use of “cuDF”, which is the GPU dataframe library within RAPIDS. It allows users to leverage GPU power to process data in their favorite format: Pandas dataframe seamlessly. We can also make use of “dask-cuDF”, which is a library that creates partitioned dataframe using Dask. When multiple GPUs are available, “dask-cuDF” can further scale Pandas-like dataframe with better performance. [4]
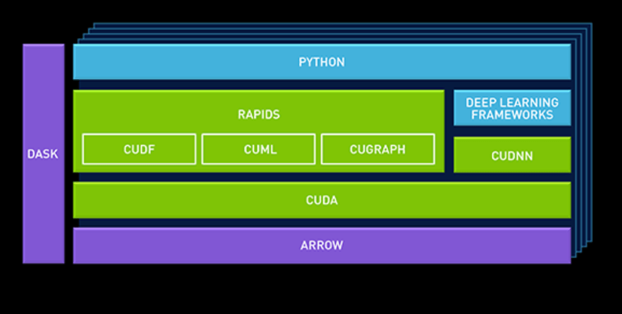
For installation, since on HPC we use containerized environment to access GPUs and RAPIDS cannot be installed inside a container [5], we need to pull a new singularity image in order to use RAPIDS. But first let’s do some experiments to see whether it’s worth our while.
Experiment
In this section we compare the performance of sample DP tasks between single-thread, multi-core (Dask) and GPU-acceleration (RAPIDS). I choose Kaggle notebook to perform the experiment because it provides multiple CPUs, one GPU and also has easy connection to various datasets.
To simulate DP pipeline, simply perform a full-pass computation on all the data. Note that to differentiate their performance, data size needs to be larger than 2GB, otherwise all results will be in the milliseconds.
By repeating a popular dataset “NYC Taxi dataset”, I created a dataset with size of 9.32GB. To time a full-pass computation, I simply performed a summation on one integer column. Full details and environment specs are in the notebook. [6] Here are the results:
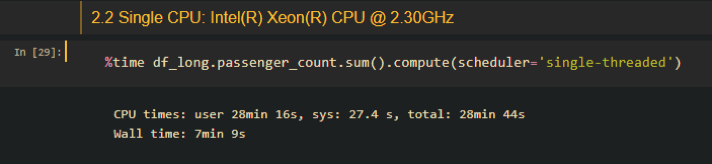
Single core:
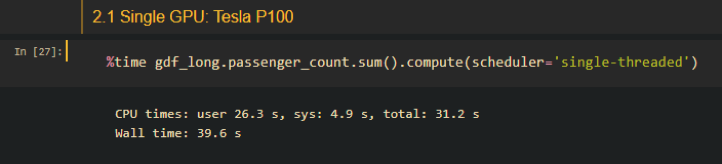
GPU:
Multi-process:
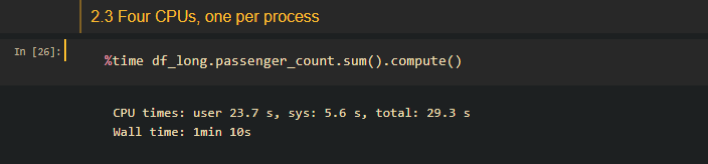
From the above screenshots we can see that even with only 4 CPUs, it is slightly more performant than GPU accelerated methods in terms of a DP computation. Consider the fact that Dask is also capable of dealing with datasets larger than memory, currently I don’t think there is a need for the use of RAPIDS and CUDA dataframes.
Conclusion
This article aims to explore several possibilities to better utilize HPC multiprocessor resources and optimizes data pre-processing pipeline for machine learning and data mining tasks alike. Through the experiment we find that Dask is powerful in terms of leveraging multiple cores in the process of DP. And on HPC clusters, generally CPUs are more accessible than GPUs, so the best practice to accelerate our DP pipeline is to use multiple CPUs. In my experience, only when we are dealing with large datasets larger than 10 million instances will single-threaded script show a poor performance. Then we can try using multi-cores with several ways introduced above.
The experiment only covers one aspect of data processing procedure, if you are not familiar with your data structure, it’s advised to run some benchmarking experiments on your own.
Contact us if you have any issues using our HPC resources, on A.S.K.
References
- (2018). Better performance with the tf.data API | TensorFlow Core. [online] Available at: https://www.tensorflow.org/guide/data_performance#optimize_performance
- dask.org. (2018). Scheduling — Dask 2.9.0 documentation. [online] Available at: https://docs.dask.org/en/latest/scheduling.html#dask-distributed-cluster
- (2018). How to Run Parallel Data Analysis in Python using Dask Dataframes. [online] Available at: https://towardsdatascience.com/trying-out-dask-dataframes-in-python-for-fast-data-analysis-in-parallel-aa960c18a915
- (2019). Here’s how you can accelerate your Data Science on GPU. [online] Available at: https://towardsdatascience.com/heres-how-you-can-accelerate-your-data-science-on-gpu-4ecf99db3430
- (2018). [WIP] ImportError: cannot import name ‘librmm’ resolved in Dockerfile. [online] Available at: https://github.com/rapidsai/cudf/pull/434
- Experiment notebook: https://gist.github.com/candy9599/79127b95e3a21a66c15ca18781f990f0
