
Accelerating Deep Learning & Other Data-Intensive GPU Applications
By Ku Wee Kiat, Research Computing, NUS Information Technology
We have recently deployed a new all-flash storage appliance for NUS HPC Clusters. This new storage system provides about 100TB of high performance parallel file storage distributed amongst users of Atlas 9 and Volta GPU clusters.
The storage system is purpose-built to accelerate Deep Learning applications (GPU) and other applications with mixed and demanding IO workloads.
In this article, we will go through how to access the storage as well as show you results from Deep Learning benchmarks we have conducted on the new storage system, existing NAS system (hpctmp) as well as Volta nodes local SSD.
Accessing the New Storage System
The new storage system is available on /scratch2 location in Atlas 9 and Volta nodes and can be accessed the same way you do with /hpctmp.
You should create your own folder in the following format: /scratch2/your_nusnet_id_here
e.g.:
/scratch2/e1010101
You can copy files directly into /scratch2 from the Atlas 9 login node.
Read/Write Benchmarks
Below are some read/write benchmarks of the various storage options available on NUS HPC currently (/hpctmp, /scratch on volta nodes and /scratch2). We performed tests for both reading and writing of various file sizes on the three storage options.
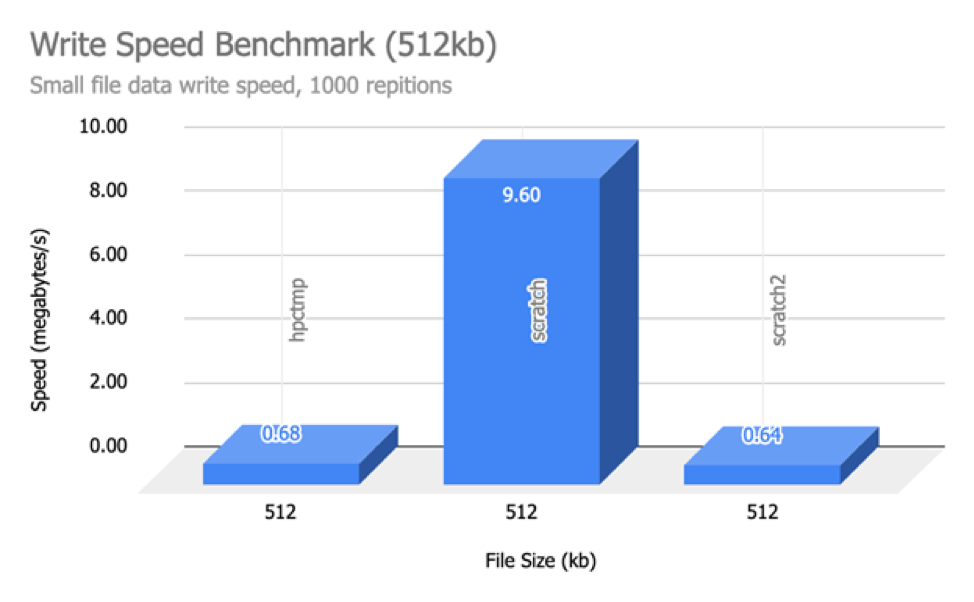
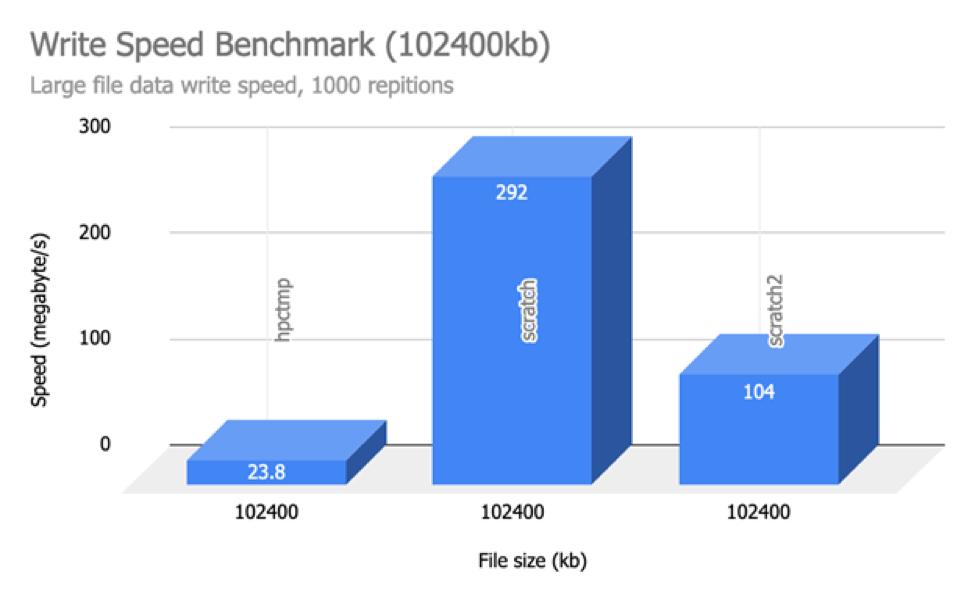
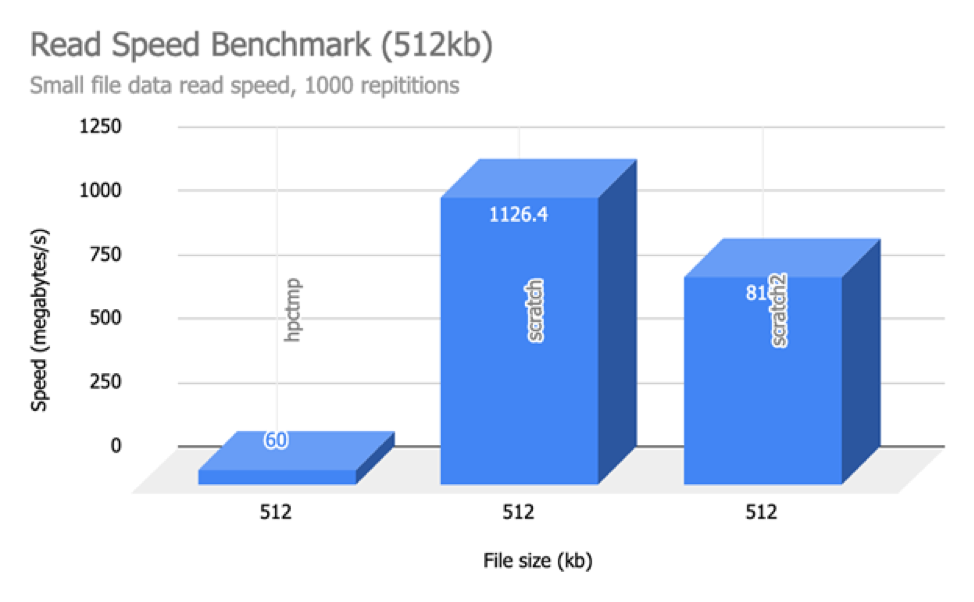
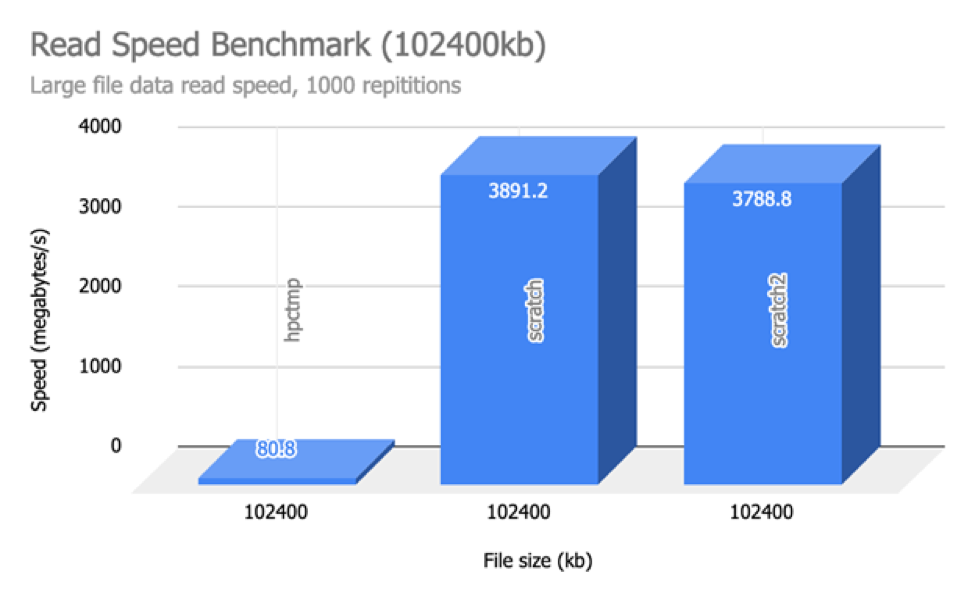
We can infer from the above results that read and writing checkpoints (for Deep Learning) will be incredibly faster on both /scratch and /scratch2 as compared to on /hpctmp.
If you feel that your data read/write patterns would be better suited for SSD than spinning hard drives, use /scratch2 or /scratch (on volta nodes).
Machine Learning Benchmark
MLPerf
We performed some benchmarks with ML Perf Image Classification tasks using Tensorflow and Imagenet dataset in TFRecords format on a singularity container on one Volta node. To get real world performance numbers, we ran the benchmarks on a live system, alongside active jobs from other HPC users. We only performed one run of the benchmark on each configuration, therefore results may vary significantly (will be affected by server load) if you were to run it on your own.
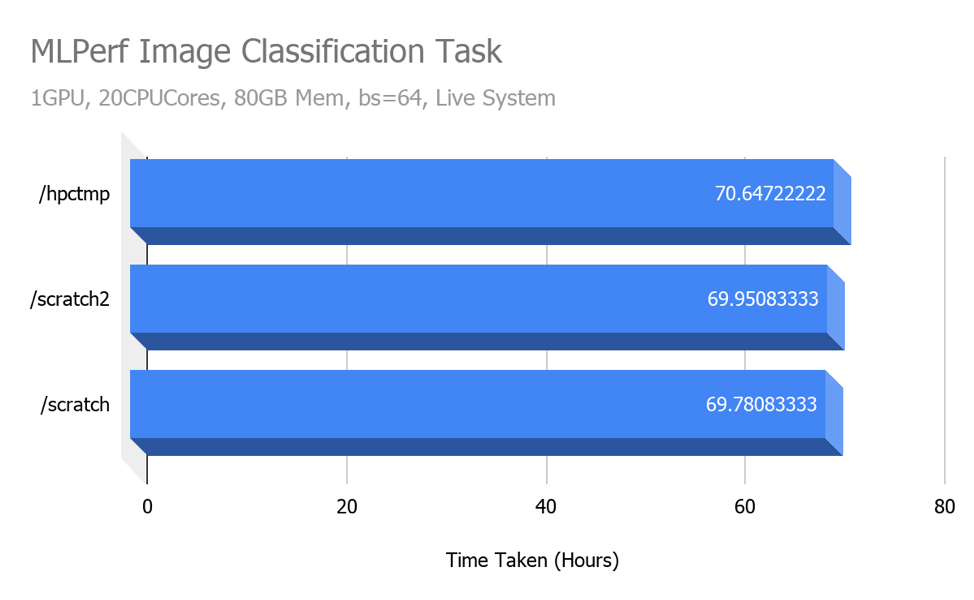
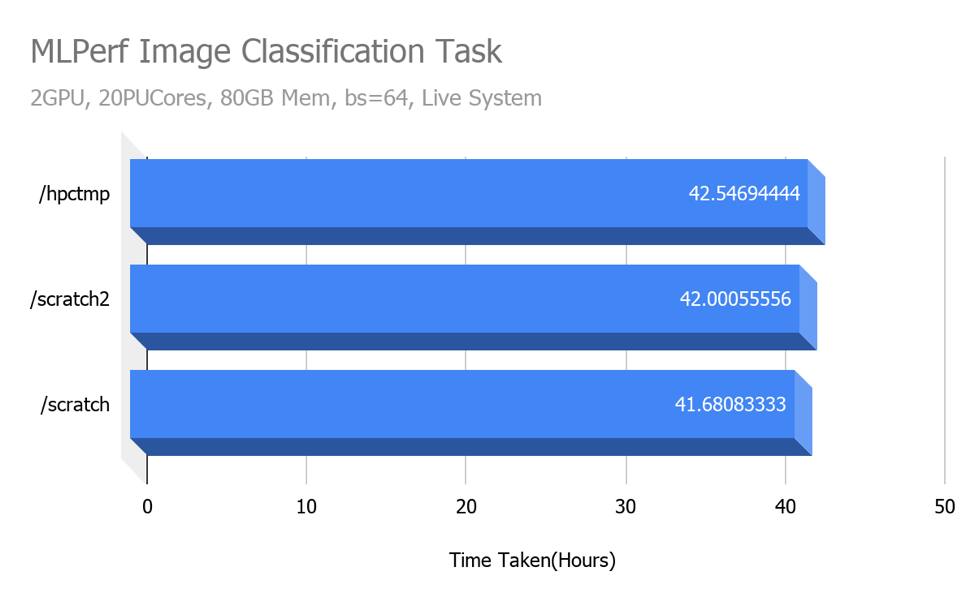
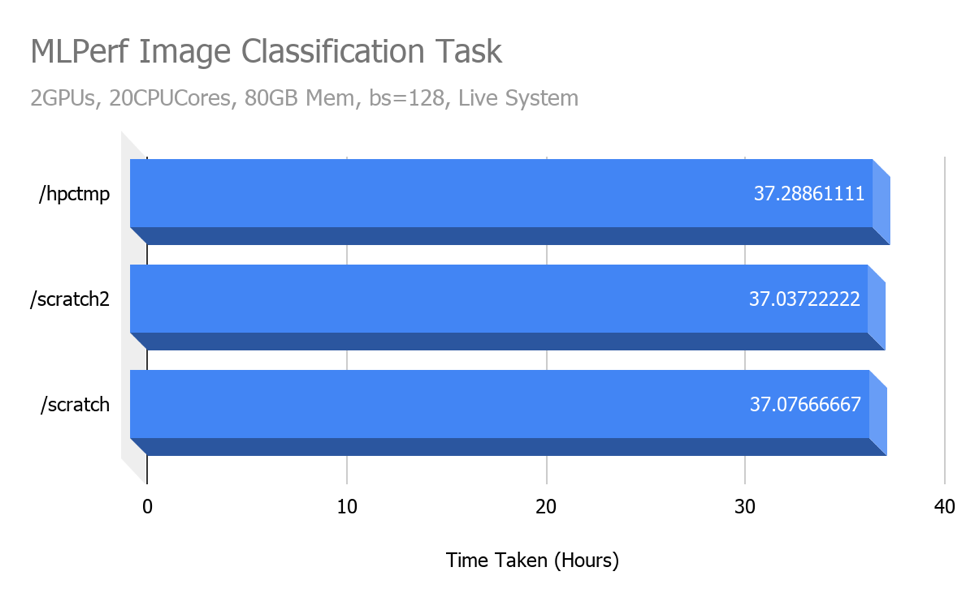
The above results are based on a dataset stored in TFRecord format, therefore datasets stored as plain image files may show different (possibly better) performance numbers on SSD and the new storage system as compared to NFS.
Findings
Even though the read/write benchmark results indicate that the all-flash local storage (/scratch) and all-flash network mounted storage (/scratch2) perform much better than the standard NAS (Network Attached Storage, /hpctmp), we don’t see any performance difference with the MLPerf benchmark. We suspect that the I/O load generated in the MLPerf wasn’t high enough to test the I/O limits of these systems.
Each of the three storage systems tested offer different degree of convenience and performance. Here is a quick guide on getting the most out of the three options:
|
|
Convenience |
I/O Performance |
Remarks |
|
/hpctmp |
High |
Standard |
Accessible from all HPC clusters |
|
/scratch2 |
Standard |
High |
Accessible from atlas9 and Volta GPU cluster |
|
/scratch |
Low |
High |
Accessible within Volta cluster node |
Different applications come with different I/O requirements and complexity. Besides knowing the characteristics of each storage system, you may also need to do the performance comparison using your own Deep Learning or GPU accelerated application. You should use the Volta GPU cluster for the comparison as it has access to all three storage systems. If there is no performance difference then stick to /hpctmp. Consider /scratch2 or /scratch only if there is significant performance improvement. Both /scratch2 and /scratch have limited capacity and it is less convenient to use.
Share with us your performance results utilising the new storage system vs the old one at dataengineering[@]nus.edu.sg. We would like to know how it impacts your research work.
