Kuang Hao, Research Computing, NUS IT
Introduction
Working with an enormous amount of textual data is always hectic and time-consuming. Hence many companies and organizations make use of Information Extraction (IE) techniques to automate the process. Information Extraction is the task of automatically extracting structured information from unstructured documents. In most of the cases, this activity concerns processing human language texts by means of natural language processing (NLP). [1]
 Unlike other popular use cases like machine translation, text classification and speech recognition, the term information extraction sounds vague and abstract. Actually, it refers to a higher level task in NLP, like text mining. Currently, there is no tool that takes an entire article as input, and churn out information according to your need. In order to extract structured knowledge/information from unstructured textual data, we need to deal with a whole pipeline of subtasks.
Unlike other popular use cases like machine translation, text classification and speech recognition, the term information extraction sounds vague and abstract. Actually, it refers to a higher level task in NLP, like text mining. Currently, there is no tool that takes an entire article as input, and churn out information according to your need. In order to extract structured knowledge/information from unstructured textual data, we need to deal with a whole pipeline of subtasks.
In this article, we will introduce common subtasks in information extraction and how to make use of opensource tools for those tasks.
Packages needed:
Preprocessing
There is always a need to process your data first, because no matter how fancy or smart your model is, the final performance is only as good as your data quality.
For web-scraped data, we need to remove the HTML tags. In other cases where data is supposed to be neat, we would still need to check for special characters, spellings and remove stop words. Then we would need to tokenize our text, which I have already introduced in the previous article.
Part Of Speech Tagging
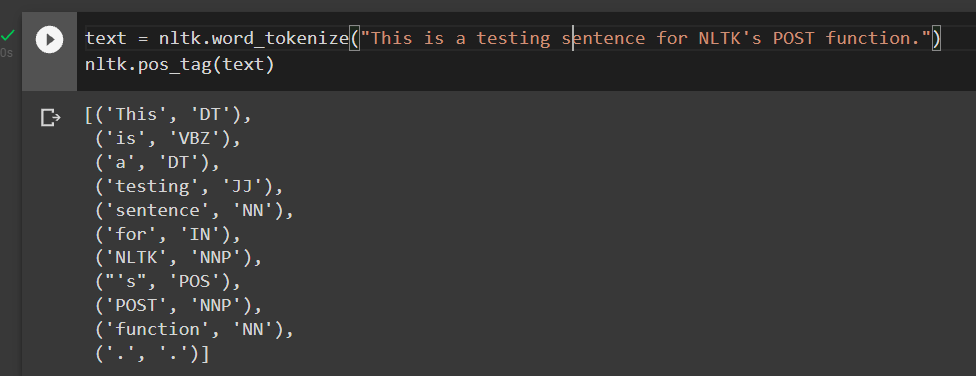
Part of speech tagging (POST) is the process of marking up words in a text corpus corresponding to a particular part of speech, based on both definition and context. This is not straightforward as a particular word can have a different POS based on context. There are many different methods for POS tagging, from lexiconbased algorithms, probabilistic models to deep learning models. The most common one embedded in NLTK make use of a Greedy Averaged Perceptron tagger, to achieve the tagging. [2] Here is an example using NLTK’s POS tagging function:
 We can also train a personalized tagger using your own dataset. In order to do so, we need to process our datasets to NLTK’s format as in the “universal_tagset”. Here shows loading a NLTK’s dataset as a reference.
We can also train a personalized tagger using your own dataset. In order to do so, we need to process our datasets to NLTK’s format as in the “universal_tagset”. Here shows loading a NLTK’s dataset as a reference.
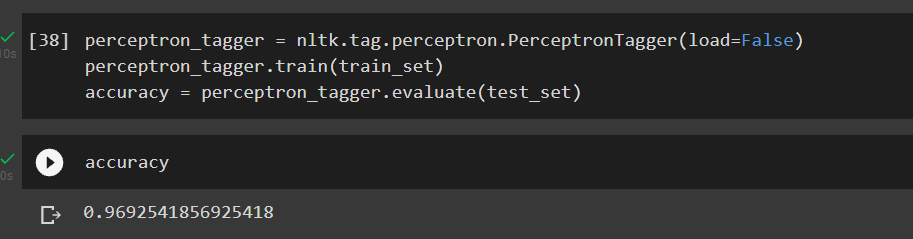
 After a train test split, we will be able to train your own tagger. In this way, our POS tagger will follow common context within our corpus. But naturally we will need to tag our own dataset nicely for such customisation.
After a train test split, we will be able to train your own tagger. In this way, our POS tagger will follow common context within our corpus. But naturally we will need to tag our own dataset nicely for such customisation.
 In practice, POS tagging is not the most common task in information extraction. But in situations where we need a method to automatically differentiate each part of a sentence, or when we need to analyse the trend of all the actions (verbs) in our data, POS tagging is the solution.
In practice, POS tagging is not the most common task in information extraction. But in situations where we need a method to automatically differentiate each part of a sentence, or when we need to analyse the trend of all the actions (verbs) in our data, POS tagging is the solution.
Name Entity Recognition
Name Entity Recognition (NER) is usually the first step towards information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organisations, locations, expressions of times, quantities, monetary values, percentages, etc. Spacy provides a user-friendly NER function that is trained on OntoNotes 5 corpus. An example using Spacy’s NER:
 Using the display function, we can visualise the above result:
Using the display function, we can visualise the above result:
 We can also train a customisd NER with Spacy, for our own custom entities present in our dataset. You can explore this tutorial to learn how to train a customised NER.
We can also train a customisd NER with Spacy, for our own custom entities present in our dataset. You can explore this tutorial to learn how to train a customised NER.
Relation Extraction
Relation Extraction (RE) is the task of extracting semantic relationships from text, which usually occur between two or more entities. [3]
There are many ways of RE, including rule-based algorithm, unsupervised RE and supervised RE. Here I would like to introduce a supervised way with Bidirectional Encoder Representations from Transformers or BERT. .BERT is a transformer-based machine learning technique for natural language processing pre-training developed by Google. For RE, the model structure is the standard BERT architecture, with some slight modifications to encode the input relation statements and to extract their pre-trained output representations for loss calculation & downstream fine-tuning tasks. [4]
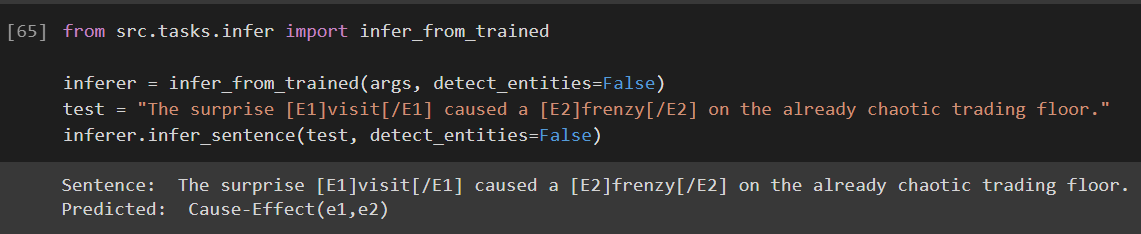
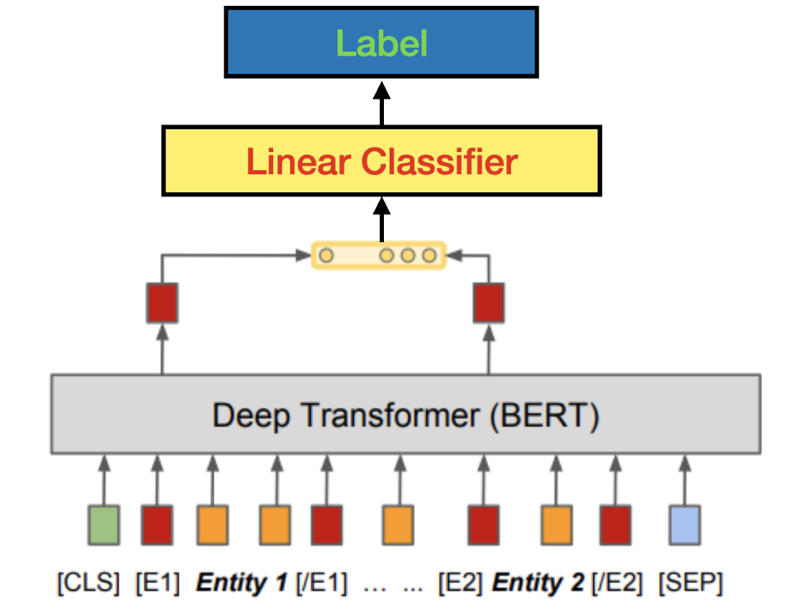 You can find the implementation here. Below is an inference example using their model:
You can find the implementation here. Below is an inference example using their model:
Conclusion
This article introduces some of the most common tasks in information extraction (or information retrieval). In reality, to extract a specific type of knowledge from documents, we might also need to make use of other techniques like topic modelling, sentiment analysis and/or text summarization.
For example, if you want to know “Which are the top rated companies mentioned in your country’s daily newspaper?” you probably need to organise your information extraction pipeline in this way: First you need to do text summarisation to get summaries of news documents. Then you need to perform sentiment analysis for them, to extract sentimental scores from the news. At the same time you would need to perform name entity recognition, in order to get the company name corresponding to each sentiment score. You may also perform POS tagging which is often coupled with NER to boost the performance. Last but not least, you would need to average the scores as more often than not, there are numerous articles talking about the same company.
Above is just a quick brainstorming example. In practice, there are many other aspects to consider, like how to get the newspaper data that mentions the companies of your target? Or how to train a customised text summarisation model to extract all the company information as well as sentiment comments that is required for your downstream work? Or even identifying aliases and acronyms to the full name of a same company? It is only after you have a valid large dataset and addresses the above challenges that you can then start to build a feasible pipeline.
I hope that through this article, you will understand the subtasks of information extraction better, and also get inspired on how to design your own text mining/information extraction pipeline.
On HPC-AI
To use the above packages on HPC-AI clusters, simply install it as a user package. The manuals for using Python on HPC-AI clusters can be found here.
Contact us if you have any issues using our HPC-AI resources, via nTouch.
References
[1]. WikiPedia. (2021).“Information extraction”. [online] Available at: https://en.wikipedia.org/wiki/Information_extraction
[2]. NLTK. (2021). “NLTK 3.6.3 Documentation”. [online] Available at: https://www.nltk.org/api/nltk.tag.html#nltk.tag.perceptron.PerceptronTagger
[3]. Medium. (2019). “Different ways of doing Relation Extraction from text”. [online] Available at:
https://medium.com/@andreasherman/different-ways-of-doing-relation-extraction-from-text-7362b4c3169e
[4]. Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling and Tom Kwiatkowski, Matching the Blanks: Distributional Similarity for Relation Learning (https://arxiv.org/pdf/1906.03158.pdf) (2019)