Improving the Generalization of Deep Networks for Image Classification
Liang Senwei
Department of Mathematics, Faculty of Science
Machine learning has become an important area of research in scientific computing. In particular, deep neural networks with powerful universal approximation and generalisation capacity get more and more attention and they are applied in many applications, such as image classification, natural language processing. I am currently engaged in deep learning on image classification and on mathematics problems. This article mainly introduces my works on improving the generalisation of deep networks for image classification.
Image classification is one of the typical machine learning problems that aims to find a function mapping an input image to its corresponding output label based on the training pairs. Deep Convolution Neural Networks (CNNs), e.g. ResNet, have been a popular tool for image classification by capturing multi-scale features. To improve the generalisation of CNNs, we have conducted some work in two directions: applying regularisation methods to reduce overfitting or designing the more effective structure.
Applying Regularisation Methods
Overfitting frequently occurs in deep learning. With the increasing depth and width of CNNs, the over-parameterised models are able to fit the training samples well but are prone to overfitting. To mitigate over-powerful fitting abilities, discarding some nonlinear activations is a possible solution. We propose a regularisation method called Drop-Activation This is a joint effort? with Khoo Yuehaw from Stanford University and my advisor Yang Haizhao.
The key idea is to drop nonlinear activation functions by setting them to be identity functions randomly during training time. At the testing stage we use a deterministic network with a new activation function to encode the average effect of dropping activations randomly.
Fig. 1 shows the standard network and network with Drop-Activation. Our theoretical analyses support the regularisation effect of Drop-Activation as implicit parameter reduction and we conduct experiments on benchmark datasets using popular architectures to show its effectiveness.
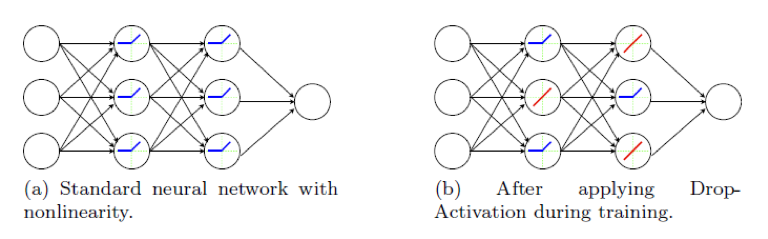
Figure 1: Left: A standard network with nonlinear activation (Blue). Right: A new network generated by applying Drop-Activation to the network on the left. Nonlinear activation functions are randomly selected and replaced with identity maps (Red) at each iteration.
Designing Effective Structure
Attention, a cognitive process that selectively focuses on a small part of information while neglects other perceivable information from learning large information contexts, has been used to effectively ease neural networks. Attention networks have successfully boosted the performance in various vision tasks. I conduct two projects studying the attention network, work together with Huang Zhongzhan from Tsinghua University, Liang Mingfu from Northwestern University and my advisor Yang Haizhao.
Firstly, we proposed a sharing mechanism framework in the attention network and considered incorporating the recurrent network placed paralleled to the network backbone. Previous works lay emphasis on designing a new attention module and individually plug them into the networks. We proposed a novel-and-simple framework that shares an attention module throughout different network layers to encourage the integration of layer-wise information. This parameter-sharing module is referred to as Dense-and-Implicit-Attention (DIA) unit.
Many choices of modules can be used in the DIA unit. Since Long Short Term Memory (LSTM) has a capacity of capturing long-distance dependency, we focused on the case when the DIA unit is the modified LSTM (called DIA-LSTM) as shown in Fig. 2. Experiments on benchmark datasets show that the DIA-LSTM unit is capable of emphasising layer-wise feature interrelation and leads to improvement of accuracy.
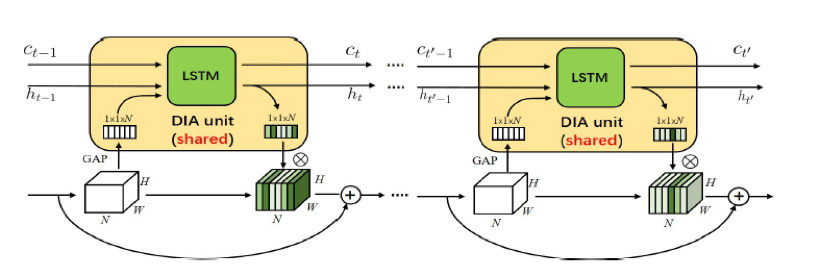
Figure 2: The showcase of DIA-LSTM. In the LSTM cell, ct is the cell state vector and ht is the hidden state vector. GAP is global average pool over channels and ⊗ is channel-wise multiplication. from LSTM will be used as an attention vector to recalibrate the channel-wise importance.
Secondly, we further studied the role of attention mechanism. Batch Normalisation (BN) normalises the features of an input image via statistics of a batch of images and hence BN will bring the noise to the gradient of training loss. We offered a new point of view that the self-attention mechanism can help to regulate the noise by enhancing instance-specific information to obtain a better regularisation effect using the experiments on style transfer and noise attack. Therefore, we proposed an attention-based BN called Instance Enhancement Batch Normalization (IEBN) that recalibrates the information of each channel by a simple linear transformation as shown in Fig. 3. IEBN has a good capacity of regulating the batch noise and stabilising network training to improve generalisation even in the presence of two kinds of noise attacks during training. Finally, IEBN outperforms BN with only a light parameter increment in image classification tasks under different network structures and benchmark datasets.
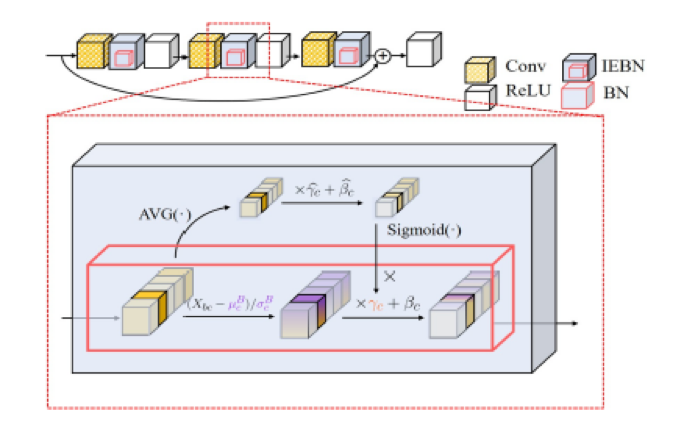
Figure 3: The illustration of IEBN. The top shows a block of ResNet. The bottom is the showcase of IEBN, where the box with red border is the basic flow of BN. AVG(●) means the average pooling over a channel and Sigmoid() is sigmoid function.
Summary
Currently, most of the works are done empirically and the nature behind the generalisation of deep networks would be interesting to study theoretically. If you are interested, you may visit my website where our works are presented at https://github.com/LeungSamWai.
Acknowledgement
I would like to thank Dr. Wang Junhong from HPC for his invitation to share my research and also express my gratitude to those in HPC who help me a lot. My overall experience of using HPC or NSCC is satisfying. The jobs are partially done with the help of HPC and NSCC computational resources.
